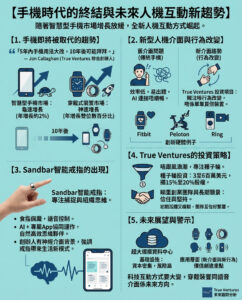
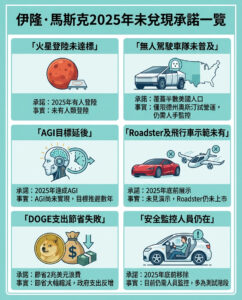
大型語言模型的局限性:為何生成式人工智慧仍需長足進步,研究人員指出
儘管生成式人工智慧(GenAI)看似非常出色,但哈佛大學、麻省理工學院、芝加哥大學和康奈爾大學的研究人員得出結論,這些大型語言模型(LLMs)並不如我們所想的那樣可靠。即使是像任天堂這樣的大公司也不願意與其遊戲開發相聯繫。
儘管這些人工智慧系統經歷了巨大的增長,但在不可預測的現實條件下,它們仍然存在不一致和不準確的問題。
為什麼生成式人工智慧模型尚未完全可靠
雖然大型語言模型在生成文本、編寫代碼及其他應用上表現出色,但當任務或環境發生變化時,它們的表現卻會大打折扣。這一缺陷使人們對這些模型在現實應用中的可信度產生疑問,因為在這些情況下,適應性和可靠性至關重要。最近的報導指出,生成式人工智慧模型在面對動態任務時,缺乏對其處理數據的內在「理解」。
檢視人工智慧在現實場景下的表現
在一項實驗中,研究人員試圖評估一個非常流行的LLM在紐約市提供方向指引的表現。在正常情況下,該人工智慧模型提供的指引幾乎是完美的,看起來非常能幹。然而,當研究人員引入路障和繞行時,模型的準確性卻大幅下降。
它無法適應新的街道佈局,甚至無法正確導航,暴露出其對城市地理的「理解」存在嚴重缺陷。這意味著,儘管LLMs可能會「學習」到現實世界的情況,但它們並未形成像人類或其他複雜系統那樣的穩固、靈活的知識結構。
大型語言模型的結構性弱點
像GPT-4這樣流行的生成式人工智慧模型是基於一種稱為變壓器(transformer)的人工智慧架構構建的。這些變壓器在巨大的語言數據集上進行訓練,以預測單詞或序列,從而給出類似人類的回應。然而,研究人員發現,這些模型雖然在預測方面表現優異,但並不意味著它們真正了解所描述的世界。
例如,一個變壓器模型可能在連接四(Connect 4)這個棋盤遊戲中非常有效地做出有效的移動,但它仍然無法理解遊戲的真正運作方式。為了解決這一問題,研究人員提出了兩個新指標,以檢查這些人工智慧模型是否能學習到連貫的「世界模型」——這種結構化的知識使它們能夠在多種情境下適當運作。他們將這些指標應用於兩個任務:在紐約市導航和玩奧賽(Othello)這個棋盤遊戲。
隨機模型的表現超越預測性人工智慧
有趣的是,研究人員發現,隨機決策的變壓器模型往往能比那些預測準確度更高的模型生成更準確的世界模型。這本身就暗示,僅僅訓練去預測序列的人工智慧模型可能並未學會理解其工作的本質。
當研究人員關閉了紐約市地圖上僅1%的街道時,人工智慧模型的準確性從接近100%降至僅67%,顯示出其在適應性方面的深層失敗。在奧賽遊戲的任務中,一個模型成功創建了一個連貫的「世界模型」,適用於奧賽的移動,但沒有一個模型真正成功地為紐約市導航形成了一個健全的模型。
對未來人工智慧發展的啟示
這些結果顯示,當前在LLM構建和評估上的方法對於開發可靠的「現實世界」人工智慧系統是不足夠的。「我們經常看到這些模型做出令人印象深刻的事情,認為它們一定對世界有所理解。我希望我們能說服人們,這是一個需要仔細思考的問題,我們不必依賴自己的直覺來回答。」一位研究人員強調,如果希望構建真正理解其部署上下文的模型,則需要發展無法簡化為預測準確度的新方法。
科學家們希望將他們的新指標應用於科學和現實問題,以尋找使LLMs更具適應性和可靠性的方法。專注於人工智慧工程中的最終洞見,可以更好地為現實應用構建系統,同時為人工智慧的改進奠定更堅實的基礎。
在這個快速發展的科技時代,對於生成式人工智慧的理解不僅僅是技術上的挑戰,更是對其在社會中角色的重新思考。未來的發展需要更多的跨學科合作,以建立更具人性化的人工智慧系統,這樣才能真正發揮其潛力,並在多樣的現實環境中有效應用。
以上文章由特價GPT API KEY所翻譯及撰寫。而圖片則由FLUX根據內容自動生成。
✨🎱 Instagram留言 →
AI即回覆下期六合彩預測
🧠 AI 根據統計數據即時生成分析
💬 只要留言,AI就會即刻覆你心水組合
🎁 完!全!免!費!快啲嚟玩!


下期頭獎號碼
📲 去 Instagram 即刻留言