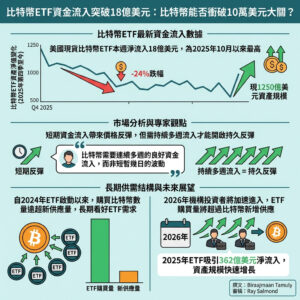
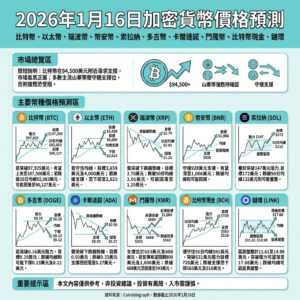
這個開源LLM可能會重新定義AI研究,並且是100%公開
什麼是由EPFL和ETH Zurich開發的開源LLM
ETH Zurich和瑞士洛桑聯邦理工學院(EPFL)推出的開源權重LLM提供了一個透明的替代方案,取代了基於綠色計算的黑箱AI,並計劃在今年晚些時候公開發布。
大型語言模型(LLMs)是能夠預測句子中下一個單詞的神經網絡,正驅動著當今的生成式AI。大多數LLM仍然是封閉的,雖然公眾可以使用,但卻無法進行檢查或改進。這種缺乏透明度與Web3的開放性和無需許可的創新原則相悖。
因此,當ETH Zurich和瑞士洛桑聯邦理工學院宣布推出一個完全公開的模型時,大家都注意到了。該模型在瑞士的碳中和“阿爾卑斯”超級計算機上訓練,並計劃在Apache 2.0授權下發布。
這個模型通常被稱為“瑞士開放LLM”、“為公共利益而建的語言模型”或“瑞士大型語言模型”,但迄今為止,尚未在公開聲明中分享具體的品牌或項目名稱。
開源權重LLM是一種模型,其參數可以下載、審核和在本地進行微調,與僅提供API的“黑箱”系統不同。
瑞士公共LLM的特點
* **規模:** 兩種配置,分別為80億和700億參數,訓練於150萬億個標記上。
* **語言:** 覆蓋1500種語言,得益於60/40的英語與非英語數據集。
* **基礎設施:** 在“阿爾卑斯”上運行的10000個Nvidia Grace-Hopper芯片,完全由可再生能源供電。
* **授權:** 開放代碼和權重,讓研究人員和初創企業都能享有分叉和修改的權利。
瑞士LLM的獨特之處
瑞士的LLM融合了開放性、多語言規模和綠色基礎設施,提供了一個徹底透明的LLM。
* **設計上開放的架構:** 與僅提供API訪問的GPT-4不同,這款瑞士LLM將在Apache 2.0授權下提供所有神經網絡參數(權重)、訓練代碼和數據集參考,讓開發者能夠自由微調、審核和部署。
* **雙模型大小:** 將以80億和700億參數版本發布,該倡議涵蓋了輕量級到大規模的使用,保持一致的開放性,而GPT-4的參數估計為1.7萬億,並未公開提供。
* **大規模多語言覆蓋:** 在150萬億個標記上訓練,支持超過1500種語言(約60%為英語,40%為非英語),挑戰GPT-4以英語為中心的主導地位,實現真正的全球包容性。
* **綠色、主權計算:** 基於瑞士國家超級計算中心(CSCS)的碳中和阿爾卑斯集群,10000個Nvidia Grace-Hopper超級芯片在FP8模式下提供超過40 exaflops的計算能力,結合了規模與可持續性,這在私有雲訓練中是缺失的。
* **透明數據實踐:** 遵循瑞士數據保護、版權法規和歐盟AI法案的透明度要求,該模型尊重爬蟲的選擇退出,卻不影響性能,彰顯了一種新的倫理標準。
完全開放的AI模型為Web3解鎖了什麼
完全的模型透明度使得鏈上推理、代幣化數據流和安全的DeFi集成成為可能,無需黑箱。
1. **鏈上推理:** 在rollup序列器中運行經過修剪的瑞士模型版本,可以實現實時智能合約摘要和欺詐證明。
2. **代幣化數據市場:** 由於訓練語料庫是透明的,數據貢獻者可以獲得代幣獎勵,並進行偏見審核。
3. **與DeFi工具的可組合性:** 開放權重允許可確定的輸出,讓預言機能夠驗證,降低了當LLM為價格模型或清算機器人提供數據時的操控風險。
這些設計目標與高意圖的SEO短語完美契合,包括去中心化AI、區塊鏈AI集成和鏈上推理,提升了文章的可發現性而不需關鍵字堆砌。
AI市場的趨勢你無法忽視
* AI市場預計將超過5000億美元,其中超過80%由封閉提供商控制。
* 區塊鏈AI預計將從2024年的5.5億美元增長到2034年的43.3億美元(年均增長率22.9%)。
* 68%的企業已經在試點AI代理,59%的人認為模型靈活性和治理是選擇的首要標準,這對開放權重是一種信心的投票。
法規:歐盟AI法案與主權模型的結合
像瑞士即將推出的公共LLM一樣,公共LLM旨在遵循歐盟AI法案,提供透明度和合規性方面的明顯優勢。
2025年7月18日,歐洲委員會發布了針對系統性風險基礎模型的指導。要求包括對抗性測試、詳細的訓練數據摘要和網絡安全審計,所有要求將於2025年8月2日生效。發布其權重和數據集的開源項目可以輕鬆滿足這些透明度要求,給公共模型帶來合規優勢。
瑞士LLM與GPT-4的比較
GPT-4在原始性能上仍然佔有優勢,這得益於其規模和專有的改進。但瑞士模型縮小了差距,特別是在多語言任務和非商業研究方面,同時提供了專有模型根本無法實現的可審核性。
阿里巴巴Qwen與瑞士公共LLM的交叉模型比較
儘管Qwen強調模型多樣性和部署性能,但瑞士的公共LLM則專注於全堆棧透明性和多語言深度。
瑞士的公共LLM並不是開源權重LLM競賽中唯一的強勁競爭者。阿里巴巴的Qwen系列,Qwen3和Qwen3-Coder,迅速成為高性能的完全開源替代品。
瑞士的公共LLM以全堆棧透明性而著稱,完全釋放其權重、訓練代碼和數據集方法,而Qwen的開放性則集中在權重和代碼上,對訓練數據來源的透明度較低。
在模型多樣性方面,Qwen提供了廣泛的選擇,包括密集模型和高級的混合專家架構(MoE),擁有多達2350億參數(220億為活躍參數),並具備更具上下文意識的混合推理模式。相比之下,瑞士的公共LLM保持了更學術的焦點,提供兩種清晰的、以研究為導向的規模:80億和700億。
在性能方面,阿里巴巴的Qwen3-Coder已被包括路透社、Elets CIO和維基百科在內的多個來源獨立基準測試,能在編碼和數學密集任務上與GPT-4相媲美。瑞士的公共LLM的性能數據仍在等待公開發布。
在多語言能力方面,瑞士的公共LLM在支持超過1500種語言方面領先,而Qwen的覆蓋範圍為119種,雖然仍然可觀,但選擇性較高。最後,基礎設施的足跡反映了不同的理念:瑞士的公共LLM運行在CSCS的碳中和阿爾卑斯超級計算機上,這是一個主權的綠色設施,而Qwen模型則通過阿里雲進行訓練和服務,優先考慮速度和規模,而非能源透明度。
以下是兩個開源LLM倡議在關鍵維度上的並排比較:
為什麼建設者應該關心
* **完全控制:** 擁有模型堆棧、權重、代碼和數據來源,無需供應商鎖定或API限制。
* **可定制性:** 通過微調針對特定領域任務進行調整,鏈上分析、DeFi預言機驗證、代碼生成。
* **成本優化:** 在GPU市場或rollup節點上部署;量化到4位可以將推理成本降低60%-80%。
* **合規性設計:** 透明的文檔與歐盟AI法案要求無縫對接,減少法律障礙和部署時間。
在使用開源LLM時需注意的陷阱
開源LLM提供了透明性,但面臨不穩定性、高計算需求和法律不確定性等挑戰。
開源LLM面臨的主要挑戰包括:
* **性能和規模差距:** 儘管架構龐大,但社區共識質疑開源模型是否能匹配封閉模型如GPT-4或Claude4的推理、流暢性和工具集成能力。
* **實施和組件不穩定性:** LLM生態系統經常面臨軟件碎片化,運行時常見版本不匹配、缺少模塊或崩潰等問題。
* **集成複雜性:** 用戶在部署開源LLM時經常會遇到依賴衝突、複雜的環境設置或配置錯誤。
* **資源密集型:** 模型訓練、托管和推理需要大量計算和內存(例如,多GPU、64GB RAM),使其對小型團隊的可及性降低。
* **文檔不足:** 從研究轉向部署的過程常常受到不完整、過時或不準確的文檔的阻礙,複雜化了採用。
* **安全和信任風險:** 開放生態系統可能容易受到供應鏈威脅(例如,通過錯字包名的攻擊)。放鬆治理可能導致後門、不當權限或數據洩露等漏洞。
* **法律和知識產權模糊性:** 使用網絡爬蟲數據或混合許可可能使用戶面臨知識產權衝突或違反使用條款的風險,這與徹底審核的封閉模型不同。
* **幻覺和可靠性問題:** 開源模型可能生成看似合理但實際上不正確的輸出,特別是在未經嚴格監督的情況下進行微調時。例如,開發者報告稱20%的代碼片段中出現了幻覺的包引用。
* **延遲和擴展挑戰:** 本地部署可能會遭遇響應時間過慢、超時或在負載下不穩定的問題,而這些問題在管理的API服務中很少見。
這篇文章不僅展示了瑞士的開源LLM如何在透明性和可持續性方面設立新標準,還強調了在AI和區塊鏈交匯處的潛在機會。隨著市場對開放性和合規性的需求日益增長,這一模型的推出可能會成為未來AI發展的重要里程碑。
以上文章由特價GPT API KEY所翻譯及撰寫。而圖片則由FLUX根據內容自動生成。