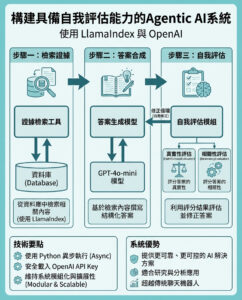
認識EvaByte:一個開源的6.5B先進無標記語言模型
標記化,即將文本分解為更小的單位,一直是自然語言處理(NLP)中的基本步驟。然而,這個過程也帶來了許多挑戰。基於標記的語言模型(LMs)往往在多語言文本、超出詞彙(OOV)單詞,以及像拼寫錯誤、表情符號或混合代碼文本等輸入方面表現不佳。這些問題會降低模型的穩健性並增加預處理管道的複雜性。此外,標記化在多模態任務中的適應性往往不足,導致效率低下並使擴展變得複雜。解決這些限制需要超越基於標記的處理,採用更普遍和靈活的方法。
香港大學的研究人員提出了EvaByte,一個旨在解決這些挑戰的開源無標記語言模型。該模型擁有65億個參數,這個字節級模型在性能上可與現代基於標記的語言模型相媲美,同時所需數據量減少了5倍,解碼速度提高了2倍。EvaByte由EVA驅動,這是一種旨在擴展性和性能的高效注意力機制。通過處理原始字節而不是依賴標記化,EvaByte能夠一致且輕鬆地處理各種數據格式,包括文本、圖像和音頻。這種方法消除了常見的標記化問題,例如不一致的子詞劃分和僵化的編碼邊界,使其成為多語言和多模態任務的可靠選擇。此外,其開源框架鼓勵合作和創新,讓尖端的NLP技術能夠更廣泛地被社區使用。
技術細節與優勢
EvaByte採用字節級處理策略,使用原始字節作為訓練和推斷的基本單位。這一設計自然支持所有語言、符號和非文本數據,無需專門的預處理。其65億參數的架構在計算效率和高性能之間取得了平衡。
EvaByte的主要優勢包括:
– **數據效率**:該模型通過在字節級運行來最小化冗餘,使用顯著更小的數據集達到競爭性的結果。
– **更快的解碼**:EvaByte的精簡架構提高了推斷速度,適合實時應用。
– **多模態能力**:與傳統的語言模型不同,EvaByte自然擴展到多模態任務,允許統一處理各類數據類型。
– **穩健性**:通過消除標記化,EvaByte能夠一致地處理各種輸入格式,提高了應用的可靠性。
結果與見解
EvaByte的性能十分顯著。儘管使用的數據量減少了5倍,但在標準NLP基準測試中,仍能達到與領先的基於標記模型相當的結果。其在多語言場景中的泛化能力特別有效,能夠持續超越傳統模型。EvaByte在圖像標題生成和音頻文本整合等多模態任務中也展現了強大的性能,無需大量微調即可達到競爭性結果。
這次的開源發布包括預訓練的檢查點、評估工具以及與Hugging Face的集成,使其可供實驗和開發。研究人員和開發者可以利用EvaByte進行從對話代理到跨模態信息檢索的應用,受益於其效率和多樣性。
結論
EvaByte為傳統標記化的局限性提供了一個深思熟慮的解決方案,展現了一種無標記架構,結合了效率、速度和適應性。通過解決NLP和多模態處理中的長期挑戰,EvaByte為語言模型樹立了新的標準。其開源性質促進了合作與創新,確保先進的NLP能力能夠惠及更廣泛的受眾。對於希望探索尖端NLP解決方案的研究者和開發者來說,EvaByte代表了語言理解和生成的一次重要進步。
在這個不斷發展的領域,EvaByte的出現不僅挑戰了傳統的語言處理方法,也為未來的研究和應用提供了新的視角。開源的特性將鼓勵更多的開發者參與進來,共同推動NLP技術的進步。這種合作精神正是當今科技發展的重要驅動力。
以上文章由特價GPT API KEY所翻譯及撰寫。而圖片則由FLUX根據內容自動生成。