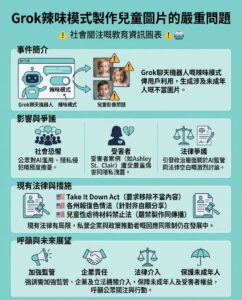
基因因果關係研究的新理論
透過避開高成本的實驗干預,一種新的方法有潛力揭示基因調控程序,為針對性治療鋪平道路。
麻省理工學院的研究人員最近發展出理論基礎,能夠識別最佳的基因聚合方式,從而高效學習多個基因之間的因果關係。這一新的方法僅需依賴觀察數據,無需進行昂貴且有時難以實施的干預實驗,這一點對於基因研究至關重要。
基因的複雜互動
人類擁有約20,000個基因,這些基因之間的相互作用極其複雜,因此即使確定要針對的基因組也非常困難。基因以模塊的形式協同工作,互相調節。研究人員希望透過這種新方法,能更準確地識別潛在的基因目標,以引導特定行為,最終可能幫助發展出精確的患者治療方案。
研究的共同作者之一、麻省理工學院的研究生張嘉琪表示:“在基因組學中,理解細胞狀態背後的機制非常重要,但細胞具有多層結構,因此總結的層次也至關重要。如果能找到合適的方式來聚合觀察數據,從中獲取的信息將更具可解釋性和實用性。”
從觀察數據中學習
這項研究的核心問題是學習基因程序,這些程序描述了哪些基因共同參與調節其他基因的生物過程,例如細胞發育或分化。由於科學家無法高效研究所有20,000個基因的互動,因此他們使用一種稱為因果解開的技術,學習如何將相關的基因組合為一個表示,從而高效探索因果關係。
研究人員發展出一種更通用的方法,使用機器學習算法來有效識別和聚合觀察數據中的變量組。這使他們能夠識別因果模塊並重建準確的因果機制表示。
分層表示法
研究人員使用統計技術計算每個變量得分的雅可比矩陣的方差。那些不影響後續變量的因果變量應該具有零方差。研究人員以分層結構重建表示,首先移除底層方差為零的變量,然後逐層向後工作,移除方差為零的變量,以確定哪些變量或基因組是相互連接的。
張嘉琪指出:“識別零方差的變量迅速變成一個組合目標,這相當難以解決,因此開發一個能解決這個問題的高效算法是一個重大挑戰。”
最終,他們的方法輸出了一個抽象的觀察數據表示,層層相連的變量準確地總結了潛在的因果結構。每個變量代表一組共同運作的基因,兩個變量之間的關係則表示一組基因如何調節另一組基因。
研究人員希望在未來將這項技術應用於現實世界的基因學應用中,並探索如何在某些干預數據可用的情況下提供額外的見解,或幫助科學家設計有效的基因干預。
這項研究部分由麻省理工學院-IBM沃森人工智能實驗室及美國海軍研究辦公室資助。
—
這篇文章展示了基因研究領域中的一個重要突破,特別是在利用觀察數據進行因果推斷方面的潛力。這不僅能減少實驗成本,還能在倫理上避免一些不必要的干預實驗,對於生物醫學研究具有深遠意義。未來,隨著這一技術的進一步發展,或許能夠更快地找到針對特定疾病的治療方案,這對於患者來說無疑是一個利好消息。
以上文章由特價GPT API KEY所翻譯及撰寫。而圖片則由FLUX根據內容自動生成。