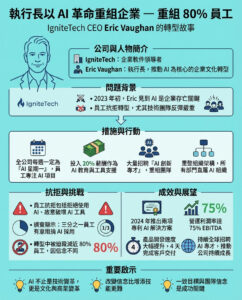
史丹福大學虛假信息專家承認使用聊天機器人導致法庭文件中的虛假信息
一位來自史丹福大學的虛假信息專家在明尼蘇達州的一宗聯邦法庭案件中被指控提交了一份包含虛構信息的宣誓聲明,並將責任歸咎於一個人工智能聊天機器人。
該名教授Jeff Hancock在一份道歉的法庭文件中表示,聊天機器人所產生的錯誤比原告所強調的錯誤更多,他並不打算誤導法庭或任何律師。他寫道:「對於可能造成的任何困惑,我深表歉意。」
代表一名YouTuber及明尼蘇達州立法者的律師在上個月的法庭文件中指出,Hancock的專家證人聲明中提及了一項根本不存在的研究,作者為Huang、Zhang和Wang。他們懷疑Hancock在準備這份12頁的文件時使用了聊天機器人,並要求法庭將該文件撤回,因為它可能還包含其他未被發現的AI虛構信息。
事實上,在律師指出Hancock的錯誤後,他發現自己在宣言中還有兩個其他的AI「幻覺」,根據他在明尼蘇達地區法庭的文件所述。
Hancock是史丹福社交媒體實驗室的創始主任,受明尼蘇達州檢察總長邀請,作為一名專家證人參與這宗由該州立法者及一位社交媒體影響者提起的訴訟。這位立法者和YouTuber正在尋求法庭命令,宣告一項將與選舉相關的AI生成「深度偽造」照片、視頻和音頻定為犯罪的州法律違憲。
Hancock的法律困境突顯了生成AI最普遍的問題之一。自2022年11月舊金山的OpenAI發布其ChatGPT聊天機器人以來,這項技術風靡全球。AI聊天機器人和圖像生成器經常會產生被稱為幻覺的錯誤,這些錯誤在文本中可能涉及虛假信息,而在圖像中則可能出現荒謬的情況,例如六指的手。
在他向法庭提交的道歉文件中,Hancock詳細說明了他使用OpenAI的ChatGPT生成專家聲明時導致的錯誤。他承認除了Huang、Zhang和Wang的虛假研究外,他還在聲明中提及了一篇「不存在的2023年文章,作者為De Keersmaecker和Roets」,以及四位「不正確」的作者。
為了增強自己專業的可信度,Hancock在文件中聲稱自己共同撰寫了「有關AI介導溝通的基礎性文章」。他寫道:「我在虛假信息方面發表了大量研究,包括虛假信息的心理動力學、其普遍性以及可能的解決方案和干預措施。」
他使用ChatGPT 4.0來幫助查找和總結文章,但錯誤可能是在他草擬文件時引入的。他在文本中插入了「引用」這個詞,以提醒自己在提出觀點時添加學術引用。他寫道:「因此,GPT-4o的回應是生成一個引用,這就是我認為幻覺引用出現的地方。」他補充說,他相信聊天機器人還編造了四位不正確的作者。
Hancock在法庭上宣誓,表示他「已經確定了所引用的學術、科學和其他材料」,而這名YouTuber及立法者在11月16日的文件中質疑Hancock作為專家證人的可靠性。
在向法庭道歉時,Hancock強調這三個錯誤「不影響他作為專家的任何科學證據或意見」。
該案件的法官已定於12月17日舉行聽證會,以決定是否應撤回Hancock的專家聲明,以及明尼蘇達州檢察總長是否可以提交更正版本。
史丹福大學的學生若未經教師許可使用聊天機器人「實質完成作業或考試」可被停學及要求社區服務,但該校並未立即回應有關Hancock是否會面臨紀律處分的問題。Hancock也未立即對類似問題做出回應。
Hancock並不是第一位提交包含AI生成無意義內容的法庭文件的人。去年,律師Steven A. Schwartz和Peter LoDuca因提交一宗人身傷害訴訟文件,內容包含由ChatGPT編造的虛假過去法庭案件以支持他們的論點,而在紐約聯邦法庭被罰款各5000美元。「我沒有理解到ChatGPT會編造案件,」Schwartz告訴法官。
評論:這個事件反映了AI技術在法律領域應用的潛在風險,尤其是在需要高可信度的專業證據時。Hancock的情況不僅揭示了生成AI在資訊準確性方面的缺陷,也突顯出學術界對於AI工具使用的道德責任。隨著AI技術的迅速發展,專業人士必須更加謹慎地檢查其結果,以免因不實信息而損害自身的專業形象及法律程序的完整性。此外,這一事件也促使我們思考AI在法律和學術領域的應用規範,如何平衡創新與責任,將成為未來討論的重點。
以上文章由特價GPT API KEY所翻譯及撰寫。而圖片則由FLUX根據內容自動生成。