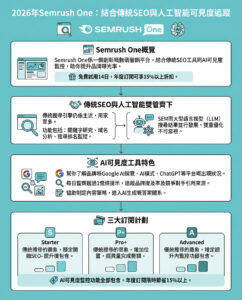
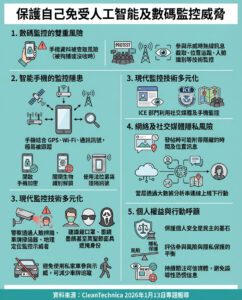
在Amazon OpenSearch Serverless和Amazon Bedrock中建立可讀取的語義緩存
在生成式人工智能領域,延遲和成本是主要挑戰。常用的大型語言模型(LLMs)通常以自回歸的方式逐個處理文本,這可能會導致延遲,影響用戶體驗。此外,對人工智能應用的需求不斷增長,導致對這些LLM的請求量激增,可能超出預算限制,給組織帶來財務壓力。
本文提出了一種優化基於LLM的應用程序的策略。考慮到對高效和成本效益的人工智能解決方案的需求,我們提出了一個無服務器的可讀取緩存藍圖,利用重複的數據模式。通過這個緩存,開發者可以有效地保存和訪問相似的提示,從而提升系統的效率和響應時間。所提出的緩存解決方案使用Amazon OpenSearch Serverless和Amazon Bedrock,這是一個完全管理的服務,提供來自AI21 Labs、Anthropic、Cohere、Meta、Stability AI和Amazon等領先人工智能公司的一系列高性能基礎模型(FMs),並通過單一API提供廣泛的功能,以構建安全、隱私和負責任的生成式AI應用程序。
解決方案概述
該緩存在此解決方案中作為緩衝區,攔截自然語言表達的請求提示,這些提示在到達主模型之前被處理。語義緩存的功能類似於記憶庫,儲存之前遇到的相似提示。它旨在高效地將用戶的提示與其最接近的語義對應項匹配。然而,在實際的緩存系統中,精確定義相似性至關重要。這一精煉過程旨在平衡兩個關鍵因素:提高緩存命中率和減少緩存碰撞。當請求的提示在緩存中找到時,即為緩存命中,這意味著系統無需將其發送到LLM進行新生成。反之,當多個提示因其語義特徵相似而映射到同一緩存位置時,即為緩存碰撞。為了更好地理解這些概念,讓我們考慮幾個例子。
想像一個由LLM驅動的禮賓AI助手,專為旅行公司設計。它擅長根據過去的互動提供個性化的回應,確保每個回覆都與旅客的需求相關且量身定制。在這裡,我們可能會優先考慮高召回率,即我們更願意有更多的緩存回應,即使這偶爾會導致重疊的提示。
現在,考慮另一種情況:一個AI助手,旨在協助該旅行公司的後台代理,使用LLM將自然語言查詢轉換為SQL命令。這使得代理能夠從發票和其他財務數據中生成報告,應用日期和總金額等過濾器,以簡化報告創建。在這種情況下,精確性是關鍵。我們需要每個用戶請求準確映射到其對應的SQL命令,沒有出錯的空間。在這種情況下,我們會選擇更嚴格的相似性閾值,以確保緩存碰撞保持在絕對最小。
本質上,可讀取的語義緩存不僅僅是中介;它是一個優化系統性能的戰略工具,根據不同應用的具體需求進行調整。無論是為聊天機器人優先考慮召回率,還是為查詢解析器優先考慮精確度,可調整的相似性特徵確保緩存在最佳效率下運作,提升整體用戶體驗。
語義緩存系統的核心運作是作為一個數據庫,儲存文本查詢的數值向量嵌入。在存儲之前,每個自然語言查詢都會轉換為相應的嵌入向量。借助Amazon Bedrock,您可以靈活選擇各種管理的嵌入模型,包括Amazon自有的Amazon Titan嵌入模型或第三方替代品,如Cohere。這些嵌入模型專門設計用來將相似的自然語言查詢映射到具有相似歐幾里得距離的向量嵌入,提供語義相似性。通過OpenSearch Serverless,您可以建立一個向量數據庫,以設置一個強大的緩存系統。
通過利用這些技術,開發者可以構建一個語義緩存,能高效地存儲和檢索語義相關的查詢,提升系統的性能和響應能力。在本文中,我們展示了如何使用各種AWS技術建立一個無服務器的語義緩存系統。這個設置允許快速查詢以檢索可用的回應,跳過耗時的LLM調用。最終結果不僅是更快的響應時間,還顯著降低了成本。
部署解決方案
這個解決方案涉及設置一個Lambda層,該層包含與OpenSearch Serverless和Amazon Bedrock等服務交互的依賴項。一個預建的層已編譯並添加到公共的Amazon S3前綴中,並在提供的CloudFormation模板中可用。您還可以選擇使用其他庫構建自己的層;有關詳細信息,請參閱以下GitHub庫。
您可以使用提供的模板來部署此解決方案,所需的角色如下:
此解決方案使用以下輸入參數:
– 嵌入模型
– LLM
– 相似性閾值
成功部署後(大約需要2分鐘),您可以獲取您的Lambda函數名稱並開始實驗。您可以在CloudFormation堆棧的輸出選項卡上找到Lambda函數名稱,如下圖所示。
您可以從Lambda控制台或通過AWS命令行界面(AWS CLI)調用Lambda函數:
“`bash
aws lambda invoke
–function-name YOUR_LAMBDA_FUNCTION_NAME
–invocation-type RequestResponse
–cli-binary-format raw-in-base64-out
–payload ‘{“prompt”: “your question here”}’
output.txt
“`
您的有效負載可以有其他選項來控制緩存和生成,如下所示:
“`json
{
“max_tokens_to_sample”: int, // 可選。控制在緩存未命中時LLM生成的長度,默認為1000。
“reset”: bool // 可選。重置緩存
}
“`
測試解決方案
要測試您的緩存,請使用Lambda控制台,打開函數頁面。導航到您從堆棧輸出中獲取的函數。設置測試事件,如下圖所示。
成功運行後,結果顯示類似於以下的屏幕截圖。
讓我們嘗試另一個實驗,以更深入地了解我們的緩存的運作。對於這個實驗,我們使用Amazon Bedrock上的Cohere嵌入模型和0.75的相似性閾值。我們問了以下問題,使用Anthropic的Claude V2生成完整回應大約花了15秒:
提示:人工智能和區塊鏈技術對全球金融行業的潛在長期影響是什麼?
生成:以下是人工智能和區塊鏈對全球金融行業的一些潛在長期影響:
– 例行任務的自動化——人工智能和機器學習可以自動化許多例行的金融任務,如貸款處理、欺詐檢測、客戶入職等。這可能會導致金融公司降低運營成本並提高效率。
– 更好的數據分析和洞察——人工智能能更有效地分析大量金融數據。這可以導致更好的洞察、為客戶提供個性化建議,並改善公司的風險管理。
– 改進的交易和投資平台——人工智能算法可以比人類交易者更快且更優化地執行交易。它們還可以使機器人顧問能夠提供自動化的投資建議和投資組合管理。
– 增強的安全性和欺詐檢測——機器學習模型可以檢測數據中的模式,以識別潛在的欺詐、洗錢或網絡安全威脅。區塊鏈提供了一個去中心化的、加密的交易記錄,難以被篡改。
當我們嘗試這些提示變體時,緩存系統成功返回了之前生成的回應(在0.5秒內):
相似提示1:人工智能和區塊鏈對全球金融行業的潛在未來影響是什麼?
相似提示2:討論人工智能和區塊鏈技術的進步在未來幾十年對全球金融格局的可能影響。
讓我們將“金融行業”一詞替換為“醫療行業”;我們期望不會發生緩存碰撞並生成新的內容:
提示:您能概述人工智能和區塊鏈對全球醫療行業的未來影響嗎?
生成:以下是人工智能對醫療行業的一些潛在長期影響:
– 個性化醫療——人工智能可以分析有關基因、生活方式、病歷等的大數據集,以提供量身定制的治療計劃,符合每位患者的需求和風險。這可以改善結果並減少系統浪費。
– 早期疾病檢測——算法在分析醫療圖像和數據方面變得非常出色,能夠比人類醫生更早識別潛在疾病和病症。這可能導致更早的治療和預防重病。
– 降低成本——人工智能有潛力自動化和簡化醫療中的許多流程,從而提高效率並降低成本。例如,人工智能聊天機器人和虛擬助手可以以遠低於人類員工的成本提供一些基本服務。
以下表格總結了在Anthropic的Claude V2上測試的查詢延遲測試結果,未命中緩存和緩存命中時的情況。
| 測試查詢 | 未命中緩存 | 命中緩存 |
| ——– | ——— | ——– |
| 您能概述人工智能和區塊鏈對全球醫療行業的未來影響嗎? | 15秒 | 0.5秒以內 |
除了延遲,您還可以為您的LLM系統節省成本。通常,嵌入模型的成本效益高於生成模型。例如,Amazon Titan Text Embedding V2的成本為每1,000個輸入標記$0.00002,而Anthropic的Claude V2為每1,000個輸入標記$0.008,每1,000個輸出標記$0.024。即使考慮到OpenSearch服務的額外成本,根據緩存數據的規模,緩存系統對許多用例來說是成本高效的。
清理
在您完成對Lambda函數的實驗後,您可以快速刪除用於構建此語義緩存的所有資源,包括OpenSearch Serverless集合和Lambda函數。為此,請在AWS CloudFormation控制台中找到您的CloudFormation堆棧並刪除它。
確保您的堆棧狀態從“刪除進行中”變更為“已刪除”。
結論
在本文中,我們指導您建立無服務器的可讀取語義緩存的過程。通過實施這裡概述的模式,您可以提高基於LLM的應用程序的延遲,同時優化成本並豐富用戶體驗。我們的解決方案允許對不同大小的嵌入模型進行實驗,方便地托管在Amazon Bedrock上。此外,它還能微調相似性閾值,以達到緩存命中率和緩存碰撞率之間的完美平衡。採用這種方法以解鎖項目的更高效率和有效性。
欲了解更多信息,請參閱Amazon Bedrock用戶指南和Amazon OpenSearch Serverless開發者指南。
以上文章由特價GPT API KEY所翻譯及撰寫。而圖片則由FLUX根據內容自動生成。