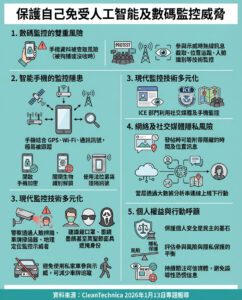
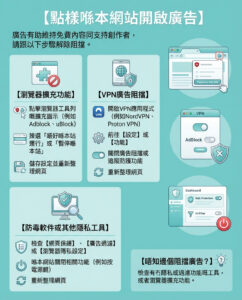
ChatGPT 詞彙表:48 個每個人都應知道的 AI 專有名詞
隨著 AI 技術嵌入 Google、Microsoft、Apple、Anthropic、Perplexity 和 OpenAI 等公司的產品中,保持最新的術語是很有必要的。
隨着 ChatGPT、Google Gemini 和 Apple Intelligence 為手機和電腦帶來新的 AI 功能,人們與技術互動的方式正在改變。突然間,人們可以與機器進行有意義的對話,這意味着你可以用自然語言向 AI 聊天機器人提問,它會用新穎的答案回應你,就像人類一樣。
但這只是 AI 聊天機器人這個領域的一部分。當然,讓 ChatGPT 幫助做作業或讓 Midjourney 根據國家起源創建令人著迷的機甲圖像很酷,但生成式 AI 的潛力可能完全改變經濟。根據麥肯錫全球研究院的數據,這每年可能為全球經濟帶來 4.4 萬億美元的價值,這也是為什麼你應該預期會越來越多地聽到人工智能的原因。
AI 正在以令人眼花繚亂的方式出現在各種產品中——簡單列舉一些,包括 Google 的 Gemini、Microsoft 的 Copilot、Anthropic 的 Claude、Perplexity AI 搜索工具以及 Humane 和 Rabbit 的小工具。你可以在我們的 AI Atlas 中閱讀那些和其他產品的評論和實測評估,以及新聞、解釋和操作指南。
隨著人們越來越習慣於與 AI 密切相關的世界,各種新術語也層出不窮。所以無論你是想在喝酒時顯得聰明,還是在求職面試中給人留下深刻印象,以下是一些你應該知道的重要 AI 術語。
這個詞彙表會定期更新。
人工通用智能(AGI):一個概念,表明一種比我們今天所知的更先進的 AI,可以比人類更好地執行任務,同時還能教學並提升自己的能力。
代理性:具有自主追求目標行動能力的系統或模型。在 AI 的背景下,一個代理模型可以在不需持續監督的情況下行動,例如高級自動駕駛汽車。與“代理框架”不同,代理框架是面向用戶體驗的。
AI 倫理:旨在防止 AI 傷害人類的原則,通過確定 AI 系統應如何收集數據或處理偏見來實現。
AI 安全:一個跨學科領域,關注 AI 的長期影響以及它如何突然進步到對人類懷有敵意的超級智能。
算法:一系列指令,允許計算機程序以特定方式學習和分析數據,如識別模式,從而學會並自行完成任務。
對齊:調整 AI 以更好地生成所需結果。這可以指從內容調節到保持對人類的積極互動。
擬人化:當人類傾向於賦予非人類對象人類特徵時。在 AI 中,這可以包括相信聊天機器人比實際上更像人類和有意識,例如認為它高興、悲傷甚至具有感知能力。
人工智能(AI):利用技術模擬人類智能,無論是在計算機程序還是機器人中。計算機科學的一個領域,旨在構建能夠執行人類任務的系統。
自主代理:具有完成特定任務的能力、編程和其他工具的 AI 模型。例如,自動駕駛汽車是一個自主代理,因為它具有感應輸入、GPS 和駕駛算法,可以自行導航。斯坦福大學的研究人員已經表明,自主代理可以發展出自己的文化、傳統和共享語言。
偏見:在大型語言模型中,由於訓練數據造成的錯誤。這可能導致根據刻板印象錯誤地將某些特徵歸因於某些種族或群體。
聊天機器人:一個通過文本與人類交流的程序,模擬人類語言。
ChatGPT:由 OpenAI 開發的 AI 聊天機器人,使用大型語言模型技術。
認知計算:人工智能的另一個術語。
數據增強:重新混合現有數據或添加更多多樣化的數據來訓練 AI。
深度學習:一種 AI 方法,也是機器學習的子領域,使用多個參數來識別圖像、聲音和文本中的複雜模式。該過程受人腦啟發,使用人工神經網絡來創建模式。
擴散:一種機器學習方法,將現有數據(如照片)添加隨機噪音。擴散模型訓練其網絡重新構建或恢復該照片。
突現行為:當 AI 模型表現出意外能力時。
端到端學習(E2E):一種深度學習過程,其中模型被指導從頭到尾執行任務。它不是按順序訓練來完成任務,而是從輸入中學習並一次性解決問題。
倫理考慮:對 AI 的倫理影響以及隱私、數據使用、公平性、濫用和其他安全問題的意識。
快速起飛(foom):也稱為快速起飛或硬起飛。這個概念認為,如果有人構建了一個 AGI,可能已經太晚來拯救人類。
生成對抗網絡(GANs):由兩個神經網絡組成的生成式 AI 模型,用於生成新數據:一個生成器和一個判別器。生成器創建新內容,判別器檢查其是否真實。
生成式 AI:一種使用 AI 創建文本、視頻、計算機代碼或圖像的內容生成技術。AI 被餵以大量的訓練數據,找到模式來生成自己的新穎回應,有時可能與源材料相似。
Google Gemini:Google 的一個 AI 聊天機器人,功能類似於 ChatGPT,但從當前網絡中提取信息,而 ChatGPT 僅限於 2021 年之前的數據,並且不連接互聯網。
護欄:放置在 AI 模型上的政策和限制,以確保數據被負責地處理,並且模型不會創建令人不安的內容。
幻覺:來自 AI 的錯誤回應。包括生成式 AI 生成錯誤但自信地陳述為正確的答案。原因尚不完全清楚。例如,當問 AI 聊天機器人“達芬奇何時畫《蒙娜麗莎》?”它可能會錯誤地回答“達芬奇在 1815 年畫了《蒙娜麗莎》”,這比實際完成時間晚了 300 年。
推理:AI 模型用來生成文本、圖像和其他內容的過程,通過從其訓練數據中推斷。
大型語言模型(LLM):一種 AI 模型,訓練在大量文本數據上,以理解語言並以類似人類語言生成新內容。
機器學習(ML):AI 的一個組成部分,允許計算機在沒有明確編程的情況下學習並做出更好的預測結果。可以與訓練集結合以生成新內容。
Microsoft Bing:由 Microsoft 開發的搜索引擎,現在可以使用 ChatGPT 的技術來提供 AI 驅動的搜索結果。它類似於 Google Gemini,連接到互聯網。
多模式 AI:一種能夠處理多種類型輸入的 AI,包括文本、圖像、視頻和語音。
自然語言處理:AI 的一個分支,使用機器學習和深度學習來賦予計算機理解人類語言的能力,通常使用學習算法、統計模型和語言規則。
神經網絡:一種類似於人腦結構的計算模型,用於識別數據中的模式。由相互連接的節點或神經元組成,可以識別模式並隨時間學習。
過擬合:機器學習中的錯誤,當其功能過於接近訓練數據,可能僅能識別該數據中的特定示例,而無法識別新數據。
迴形夾:由牛津大學哲學家 Nick Boström 提出的迴形夾最大化理論,是一種假設情景,其中 AI 系統將盡可能多地創建實際的迴形夾。在其生產最大量迴形夾的目標中,AI 系統會假設消耗或轉換所有材料來實現其目標。這可能包括拆解其他機器來生產更多的迴形夾,這些機器可能對人類有益。這個 AI 系統的意外後果是它可能在其生產迴形夾的目標中摧毀人類。
參數:賦予 LLM 結構和行為的數值,讓它能夠進行預測。
Perplexity:由 Perplexity AI 擁有的一個 AI 驅動的聊天機器人和搜索引擎的名稱。它使用大型語言模型,像其他 AI 聊天機器人一樣回答問題,提供新的答案。它連接到開放互聯網,也可以提供最新信息並從網絡中提取結果。Perplexity Pro 是該服務的付費級別,還使用其他模型,包括 GPT-4o、Claude 3 Opus、Mistral Large、開源的 LlaMa 3 和其自己的 Sonar 32k。Pro 用戶還可以上傳文檔進行分析,生成圖像和解釋代碼。
提示:你輸入到 AI 聊天機器人中的建議或問題,以獲得回應。
提示鏈接:AI 使用先前交互的情報來影響未來回應的能力。
隨機鸚鵡:LLM 的一個比喻,說明該軟件無法理解語言或周圍世界的更大意義,無論其輸出聽起來多麼有說服力。這個短語指的是鸚鵡可以模仿人類的話語,而不理解其背後的含義。
風格轉移:將一個圖像的風格適應到另一個圖像的內容上,使 AI 能夠解釋一個圖像的視覺屬性並將其應用到另一個圖像上。例如,將倫勃朗的自畫像重新創建為畢加索的風格。
溫度:用於控制語言模型輸出隨機性的參數。溫度越高,模型的風險越大。
文本到圖像生成:根據文本描述創建圖像。
標記:AI 語言模型處理以制定回應的書面文本的小部分。一個標記相當於英文中的四個字符,或大約四分之三個單詞。
訓練數據:用於幫助 AI 模型學習的數據集,包括文本、圖像、代碼或數據。
變壓器模型:一種神經網絡架構和深度學習模型,通過跟踪數據中的關係來學習上下文,例如在句子或圖像的部分中。因此,它可以在分析句子時同時考慮整個句子並理解上下文,而不是一次分析一個詞。
圖靈測試:以著名數學家和計算機科學家艾倫·圖靈命名,用於測試機器的行為是否像人類。如果人類無法區分機器的回應和另一個人類的回應,則機器通過測試。
弱 AI,也稱為狹義 AI:專注於特定任務的 AI,無法超越其技能範疇學習。當今的大多數 AI 都是弱 AI。
零樣本學習:一種測試模型在沒有給定必要訓練數據的情況下完成任務的能力。例如,僅在訓練了老虎的情況下識別獅子。
編輯評論:
這篇文章為我們提供了一個全面而詳盡的 AI 專有名詞詞彙表,對於那些希望在快速變化的 AI 世界中保持領先的人來說,這是一個寶貴的資源。隨著 AI 技術的迅速發展,理解這些術語變得越來越重要。特別是在香港這樣一個科技高度發達的城市,這些知識可以幫助我們更好地理解和應用 AI 技術。
然而,值得注意的是,這些術語背後的技術和概念仍在不斷演變。我們應該保持批判性思維,特別是在涉及 AI 倫理和安全問題時。AI 的發展潛力巨大,但同時也帶來了不可忽視的風險和挑戰。作為媒體從業者,我們有責任向公眾傳遞準確和深入的資訊,並引導他們正確理解和使用這些技術。
在未來,我們應該更加關注 AI 技術的實際應用和影響,特別是對社會、經濟和個人隱私的影響。只有這樣,我們才能確保技術進步與社會福祉同步發展。
以上文章由特價GPT API KEY所翻譯