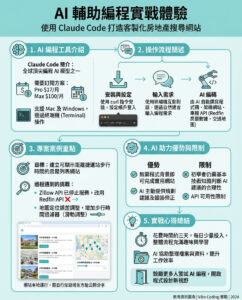
在手機上本地部署DeepSeek和大型AI模型,打造驚人的AI應用
在移動設備上直接運行大型語言模型(LLMs),例如Deepseek,正在改變AI的生態系統。通過支持本地推斷,您可以減少對雲基礎設施的依賴,降低運營成本,並支持離線應用。這篇由AI Jason撰寫的指南探討了在移動設備上部署LLMs的基本要點,包括硬件考量、部署框架、實施策略和實際應用。
無論您是要構建聊天應用、探索離線AI用例,還是對技術要求感到好奇,Jason都會為您提供幫助。通過這篇文章,您將會明白在本地運行模型不僅僅是一項技術成就——它是一種實用且具成本效益的解決方案,讓您和用戶都能掌控。想像一下,能夠在智能手機上直接利用像Deepseek這樣的先進AI模型,而不必擔心網絡連接或高昂的雲服務費用。
為什麼要在移動設備上部署LLMs
總結要點:
– 在移動設備上部署大型語言模型(LLMs)可以實現本地推斷,降低延遲,增強隱私,降低成本,並支持離線功能。
– 關鍵的硬件考量包括確保足夠的內存(例如,VRAM),並優化模型精度(例如,FP16),以平衡性能和資源使用。
– 像Termux(Android)和Apple MLX(iOS)這樣的框架簡化了部署過程,使開發者能夠有效地將LLMs整合到移動應用中。
– 開發者可以利用本地LLM部署構建聊天機器人、離線翻譯工具和教育應用,以改善用戶體驗。
– 記憶體限制和兼容性問題等挑戰可以通過量化、大規模測試和平台特定的調試工具來解決。
在移動設備上部署LLMs帶來了幾個明顯的優勢:
– **性能提升**:本地推斷消除了由雲通信引起的延遲,確保更快、更可靠的響應時間。
– **隱私增強**:用戶數據保留在設備上,減少了與外部伺服器的接觸,增強數據安全性。
– **成本效率**:將計算卸載到用戶設備上,降低了伺服器和帶寬開支,使應用更加可持續。
– **離線功能**:應用能在網絡連接有限或沒有的地區無縫運行,擴大其可用性。
對於開發者來說,這種方法開啟了創建靈活、具成本效益和以用戶為中心的應用的機會,滿足不同用戶的需求。
關鍵硬件考量
在移動設備上部署LLM之前,評估硬件能力以確保平穩運行至關重要。主要要考慮的因素是內存,特別是VRAM(視頻內存),它在推斷過程中存儲模型參數和激活內存。內存需求取決於模型大小和精度格式:
– **FP32(32位精度)**:提供高準確性,但需要大量內存資源,使其在移動設備上不太實用。
– **FP16(16位精度)**:在內存效率和性能之間取得平衡,使其成為移動部署的更合適選擇。
例如,一個擁有70億參數的FP16模型大約需要14GB的VRAM,而同樣的模型在FP32下可能需要雙倍的內存量。像VRAM估算器這樣的工具可以幫助確定特定設備是否能有效處理模型。此外,配備先進GPU或NPU(神經處理單元)的現代移動設備更能支持LLMs。
如何在移動設備上本地部署Deepseek
使用專門為特定平台設計的框架來本地部署LLMs。這些框架簡化了集成過程並優化性能:
– **Android**:Termux是一個基於Linux的終端模擬器,允許您創建本地環境以運行LLMs。它支持基於Python的API和庫,提供靈活的集成和定制。
– **iOS**:Apple的MLX框架提供將機器學習模型集成到iOS應用中的工具,確保與Apple生態系統的兼容性,包括無縫的App Store集成。
這些框架使開發者能夠構建不依賴外部伺服器的LLM應用,確保更好的性能和用戶隱私。
逐步部署過程
在移動設備上部署LLMs的過程因平台而異。以下是Android和iOS的步驟:
**對於Android:**
1. 從Google Play商店或其他來源安裝Termux。
2. 通過安裝Python、必要的庫和依賴來設置環境。
3. 下載LLM模型,並使用Hugging Face Transformers等API配置本地推斷。
4. 通過調整模型精度(例如,FP16)和批量大小來優化內存使用,以適應設備能力。
**對於iOS:**
1. 使用Xcode創建新的iOS項目並集成Apple MLX框架。
2. 使用Core ML工具將LLM模型轉換為Core ML兼容格式。
3. 在模擬器或物理設備上測試應用,以確保平穩性能和兼容性。
4. 調試並解決與內存使用或硬件限制相關的問題。
通過遵循這些步驟,您可以高效地在移動設備上部署LLMs,同時確保最佳性能。
構建聊天應用
在移動設備上LLMs最常見的用例之一是創建聊天應用。這些應用利用LLMs的能力提供智能和上下文感知的互動。以下是構建聊天應用的步驟:
1. **設計界面**:創建用戶友好的界面,支持上下文感知的對話歷史和直觀的導航。
2. **實施標記化**:將文本分解為可管理的單元,以便模型高效處理,確保準確的響應。
3. **啟用流式響應**:在對話過程中提供實時反饋,以增強用戶體驗和參與感。
4. **集成模型**:使用Hugging Face等平台訪問預訓練模型,根據用戶需求擴展功能。
通過優化性能和內存使用,您可以確保即使在資源有限的設備上也能提供流暢和響應迅速的用戶體驗。
應對挑戰
在移動設備上部署LLMs面臨獨特挑戰,但可以通過正確的策略來解決:
– **內存限制**:使用量化技術,例如將模型精度降低到FP16或INT8,以減少模型大小而不顯著影響準確性。
– **兼容性問題**:在各種設備上測試應用,以識別和解決硬件特定問題,確保一致的用戶體驗。
– **調試**:使用平台特定的調試工具,例如iOS的Xcode Instruments或Android Studio Profiler,來識別和修復性能瓶頸。
通過主動應對這些挑戰,您可以創建在不同設備和環境中表現良好的穩健應用。
本地LLM部署的應用
在移動設備上本地部署LLMs開啟了創新應用的廣泛可能性:
– **AI驅動的聊天機器人**:增強客戶支持和個人助手功能,實現智能的實時互動。
– **離線翻譯工具**:提供無需互聯網依賴的語言翻譯能力,特別適合旅行或偏遠地區。
– **教育應用**:提供個性化的學習體驗,根據個別用戶的需求進行調整,提高參與度和學習效果。
– **醫療解決方案**:啟用離線診斷工具或症狀檢查器,優先考慮用戶隱私和可及性。
通過利用用戶設備的計算能力,開發者可以創建既具創新性又具可及性的應用,滿足各種用例的需求。
發布您的應用
一旦您的應用完全開發和測試完成,最後一步是將其發布到相應的應用商店。以下是iOS部署的概述:
1. 確保應用符合Apple的指導方針,包括隱私、安全和性能標準。
2. 使用Xcode生成版本並將其上傳到App Store Connect以便分發。
3. 提交應用以進行審查,並針對Apple審查團隊的反饋進行調整,以確保獲得批准。
成功提交將確保您的應用觸及廣泛受眾,為用戶提供本地LLM部署的好處。
這篇文章深入探討了在移動設備上部署大型AI模型的技術細節,展示了當今科技如何使這一切成為可能。隨著智能手機的計算能力不斷增強,未來的應用將不再受限於雲端服務,開發者能夠更靈活地設計出符合用戶需求的解決方案。這不僅是技術的進步,更是對用戶隱私和數據安全的重視,未來的應用將會更加人性化、智能化。
以上文章由特價GPT API KEY所翻譯及撰寫。而圖片則由FLUX根據內容自動生成。
🖼️ AI 圖庫|抄咒語學玩法
想睇吓人哋點玩 AI 畫圖?圖庫集合大量 Flux / Gemini 作品, 可以一 click 複製咒語,直入生成器再改做自己版本。
 Gallery
Gallery
 Gallery
Gallery
 Gallery
Gallery