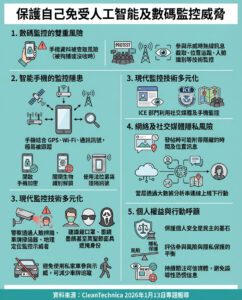
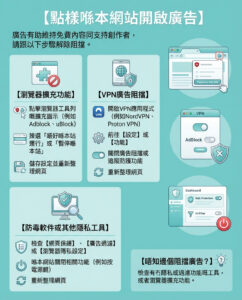
微軟AI引入Activation Steering:一種改進大型語言模型指令遵循的新方法
近年來,大型語言模型(LLMs)在各種應用中展示了顯著的進步,從文本生成到問答系統。然而,一個關鍵的改進領域是確保這些模型在任務中能準確地遵循具體指令,如調整格式、語氣或內容長度。這對於法律、醫療或技術領域等行業尤為重要,因為這些行業生成的文本必須嚴格遵循指導原則。
語言模型在文本生成過程中無法始終如一地遵循詳細用戶指令是一個主要問題。雖然模型可能能理解一般提示,但它們往往難以遵守更具體的限制,如格式要求、內容長度或某些詞語的包含或排除。這種模型能力與用戶期望之間的差距對研究人員提出了重大挑戰。在處理涉及多個指令的複雜任務時,當前的模型可能會隨著時間的推移偏離初始限制,或者根本無法應用它們,從而降低了輸出的可靠性。
多次嘗試已經針對這個問題,主要通過指令調整方法進行解決。這些方法涉及在嵌入指令的數據集上訓練模型,使其能夠在實時任務中理解並應用基本限制。然而,儘管這種方法顯示出一定的成功,但它缺乏靈活性,難以應對更複雜的指令,尤其是在同時應用多個限制時。此外,指令調整模型通常需要使用大型數據集進行重新訓練,這既耗時又資源密集。這一限制減少了它們在快速變化的現實場景中進行快速調整指令的實用性。
ETH Zürich和微軟研究院的研究人員引入了一種新方法來解決這些限制:Activation Steering。這種方法不再需要為每組新指令重新訓練模型,而是引入了一種動態解決方案來調整模型的內部運行。研究人員通過分析語言模型在給定指令和未給定指令時行為的差異,計算出捕捉所需變化的特定向量。這些向量可以在推理過程中應用,指導模型遵循新限制,而無需對模型的核心結構進行任何修改或在新數據上重新訓練。
Activation Steering通過識別和操控模型內部負責指令遵循的層來運行。當模型接收輸入時,它會通過多層神經網絡進行處理,每一層都會調整模型對任務的理解。Activation Steering方法在這些層的關鍵點追蹤這些內部變化並應用必要的修改。這些引導向量類似於控制機制,幫助模型保持在指定指令的軌道上,無論是格式化文本,限制其長度,還是確保某些詞語的包含或排除。這種模塊化方法允許進行細粒度控制,使得在推理時調整模型行為成為可能,而無需進行廣泛的預訓練。
在Phi-3、Gemma 2和Mistral三個主要語言模型上進行的性能評估顯示了Activation Steering的有效性。例如,即使在輸入中沒有明確指令,模型也顯示出改進的指令遵循,準確性比其基線性能提高了最多30%。當提供明確指令時,模型的限制遵循準確性更高,達到了60%到90%。實驗集中於幾種類型的指令,包括輸出格式、詞語包含或排除以及內容長度。例如,當要求生成特定格式的文本(如JSON)時,使用Activation Steering的模型比不使用這種方法時更能保持所需結構。
一個關鍵發現是,Activation Steering允許模型同時處理多個限制。這是對以往方法的一個重大改進,因為以往方法在同時應用多個指令時往往失敗。例如,研究人員展示了一個模型可以同時遵循格式和長度限制,這在早期方法中難以實現。另一個重要結果是引導向量在模型之間的可轉移性。計算在指令調整模型上的引導向量成功應用於基礎模型,無需額外重新訓練即可提高其性能。這種可轉移性表明,Activation Steering可以增強不同應用中的廣泛模型,使這種方法具有高度的靈活性。
總之,這項研究在NLP領域提供了一個可擴展、靈活的解決方案,以改善語言模型的指令遵循。通過使用Activation Steering,ETH Zürich和微軟研究院的研究人員展示了模型可以動態調整以遵循特定指令,增強了其在需要高精度和遵循指導原則的現實應用中的可用性。這種方法不僅提高了模型同時處理多個限制的能力,而且減少了廣泛重新訓練的需求,提供了一種更高效的控制語言生成輸出的方式。這些發現為在需要高精度和嚴格遵循指導原則的領域中應用大型語言模型開啟了新的可能性。
編輯評論:
這篇文章揭示了一個在NLP領域的重大突破,即如何在不重新訓練模型的情況下動態調整其行為。這不僅提高了模型的效率,還提供了更大的靈活性,特別是在需要快速適應和多重指令的情況下。對於香港的讀者而言,這種技術的應用可以在法律、醫療等嚴謹的行業中大有作為,確保生成的文本能夠符合特定標準,進一步提高自動化系統的可靠性和實用性。這項技術的發展也顯示出人工智能在處理複雜指令時的潛力,未來或許能夠應用於更多領域,帶來更廣泛的影響。
以上文章由特價GPT API KEY所翻譯