想像一個AI專家團隊,能夠即時應對新任務,學習快又不忘記舊技能,這就是稀疏混合專家模型的魔力!
學習路徑
- 第一課:專家團隊的魔法 — 稀疏混合專家基礎
- 第二課:持續學習嘅挑戰 — 專家團隊點樣進化?
- 第三課:終極目標 — 少樣本任務推斷嘅超能力
第一課:專家團隊的魔法 — 稀疏混合專家基礎
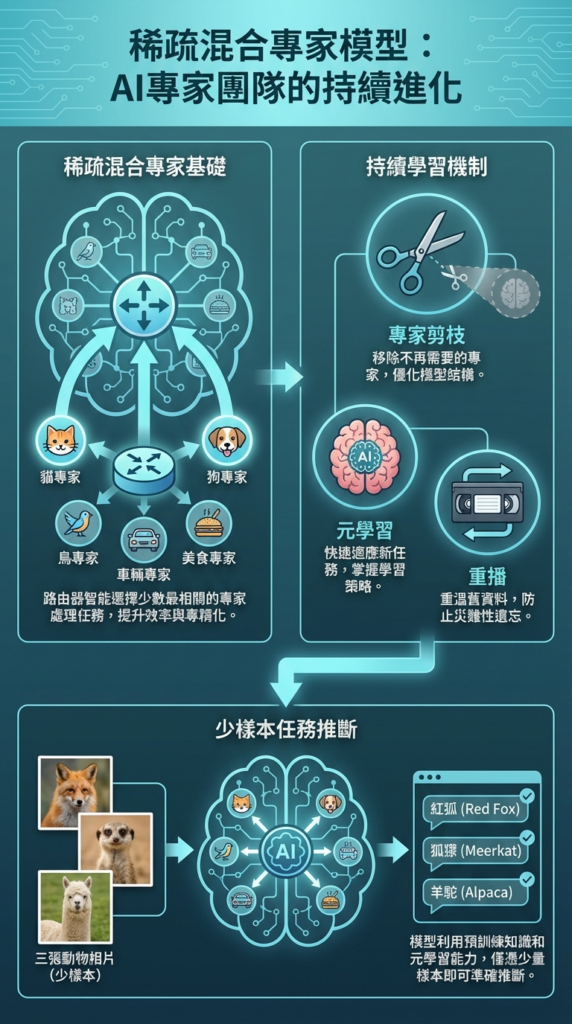
嗨!今日我哋要學一個超酷嘅AI概念:稀疏混合專家模型。想像你哋有一個超級大公司,但唔係所有員工都同時做嘢,而係根據任務搵最啱嘅專家出嚟做。咁樣冇浪費資源,又快又準!
稀疏混合專家模型就係呢個概念嘅AI版本。一個巨型AI模型入面,其實有好多個「專家」(即係細細嘅神經網路)。當有任務嚟嘅時候,一個「路由器」會決定邊幾個專家最識做,然後得呢啲專家啟動。其他專企就瞓覺慳力!呢個就係「稀疏」嘅意思 — 唔使所有專家都同時運作。
咁有咩好處?第一,慳電慳計算力;第二,每個專家可以做到自己嘅專業,好似醫生分心臟科、皮膚科咁。例如一個專家專門識貓,另一個專門識狗。當你問貓嘅問題,路由器會自動搵貓專家,唔會騷擾狗專家。
呢個設計令AI模型可以做到「條件計算」 — 冚家唚唔使做晒所有嘢,只係做需要嘅部分。好似你煮飯唔使開晒所有爐頭,只開需要嘅嗰個咁!下堂我哋會講點樣令呢啲專家團隊學識新嘢。記住:專家團隊,分工合作,效率超高!
思考題: 問題1:如果一個AI模型有100個專家,但每次任務只啟動2個,咁樣有咩優點?
第二課:持續學習嘅挑戰 — 專家團隊點樣進化?
歡迎返嚟第二堂!上堂我哋知混合專家模型好似一個專家團隊,但係如果公司要學新業務,點樣先唔會忘記舊技能呢?呢個就係「持續學習」嘅大挑戰!
想像你學完廣東話,跟住學日文,但學日文嘅時候竟然開始忘記廣東話!AI模型都會有呢個「災難性遺忘」問題。但係稀疏混合專家模型有妙計:
1. **專家剪枝**:好似園丁修剪樹枝咁,我哋會定期移除冇用嘅專家,保留最強嘅。咁樣模型唔會愈變愈臃腫。
2. **元學習**:教專家「點樣學習」。好似教一個學生唔係背答案,而係學解題方法。當新任務嚟,專家可以好快適應。
3. **重播與正則化**:重播就好似溫習功課,定期溫習舊任務;正則化就好似定立規矩,確保新學習唔會影響舊專家。
比喻:你有一個工具箱,每件工具(專家)都專門做某啲嘢。當你要學新技能,唔會改造所有工具,只係加一件新工具,或者改良舊工具少少。咁樣你嘅工具箱會愈嚟愈強大,但唔會搞亂原本嘅工具!
下堂我哋會整合所有概念,睇吓呢啲專家團隊點樣實際應用喺少樣本學習!記住:持續進化,唔會失憶!
思考題: 問題2:如果一個專家團隊要學識識別10種新動物,但只有每種動物3張相,混合專家模型點樣做到唔會忘記原本識嘅動物?
第三課:終極目標 — 少樣本任務推斷嘅超能力
終極堂嚟啦!今日我哋要睇吓稀疏混合專家模型點樣發揮「少樣本學習」嘅超能力 — 即係得幾個例子就識做新任務!
想像你教一個細路識「獨角獸」,你唔使佢睇100張相,可能得3張佢就識。點解?因為佢腦入面已經有「馬」、「角」呢啲基礎概念,可以組合起嚟理解新嘢。
混合專家模型就係咁做:
1. **動態專家選擇**:當新任務嚟,路由器會分析任務特徵,然後搵出最相關嘅專家組合。例如識「獨角獸」可能會啟動「馬專家」+「角專家」。
2. **快速適應**:透過元學習,專家已經預先訓練好「點樣快啲學新嘢」。好似運動員做好熱身運動,比賽時可以即時發揮。
3. **演化的專家庫**:模型好似一個活嘅生態系統,新專家會加入,舊專家會優化。最終變成一個超大型專家集團,每個專家都係自己領域嘅大師。
實際應用:醫療AI可能得一張罕見病嘅X光片就要診斷;語音助理可能聽你講兩句新方言就識翻譯。呢啲都係因為模型背後有千千萬個專家隨時待命!
總結:稀疏混合專家模型令AI好似一個不斷成長嘅超級大腦,分工精細,學習高效,永唔遺忘。你哋而家係呢個未來科技嘅專家啦!
思考題: 問題3:如果一個混合專家模型要應對一個全新領域(例如外星生物識別),但只得一張相,佢點樣可能做到預測?