📚【AI 寫作革命】Fiction.LiveBench:首個專為長篇小說創作設計的 LLM 測試(2025年4月)
🔗 原文連結:Fiction.LiveBench April 14, 2025
在眾多大型語言模型(LLM)強調「長上下文理解」能力的當下,Fiction.live 推出了業界首個真正以小說創作為核心的評測基準 —— Fiction.LiveBench。這是一個面向真實應用場景的評測,目的是協助寫作者了解哪個 AI 模型能真正「讀懂故事、角色與情感糾葛」。
✍️ 測試動機:現今 LLM 的長篇閱讀力仍嚴重不足
Fiction.live 作為協助作家撰寫大綱、時間線、角色設定等工具的網站,發現一個重大痛點:
「大多數 LLM 雖然聲稱支援超長上下文,但實際在情節追蹤、角色轉變、潛台詞理解方面仍頻頻失誤。」
因此他們發起了 Fiction.LiveBench,針對多部極其複雜的長篇小說進行改編與測試,模擬真實寫作中 LLM 所需處理的挑戰。
🧪 測試方法:比現有的 LongBench 更貼近實戰
測試並非單純考驗「搜尋能力」,而是真正測量模型能否理解:
- 人物關係變化(如:愛恨轉折)
- 埋下的伏筆是否被成功掌握
- 哪些訊息是讀者知道而角色不知道(角色視角與敘事視角差異)
- 情節邏輯與心理動機
他們設計出不同長度(從 0 token 簡化版本到 120k token 完整故事)的測試版本,評估模型在不同上下文長度的表現差異。
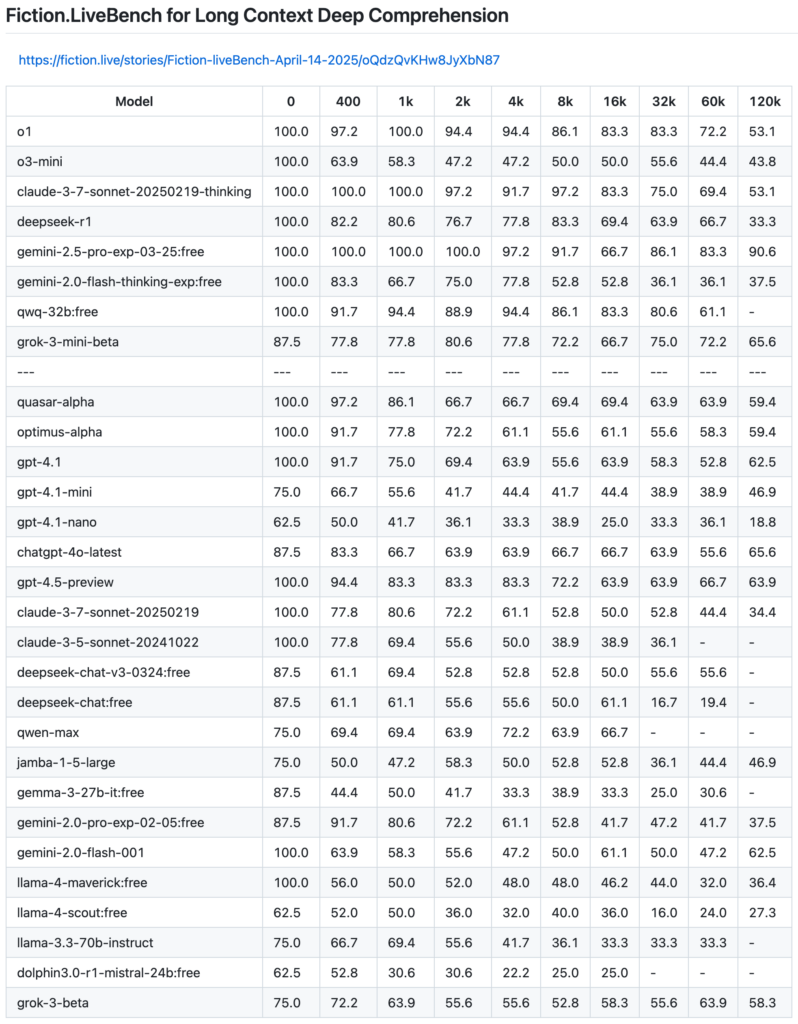
📈 測試重點結果
💡 關鍵發現:
- Google Gemini 2.5 Pro 是目前唯一一款在120k token 長文測試下仍維持 90 分以上準確率的模型,堪稱首次可實際用於長篇寫作的 AI。
- Claude 3.7 Sonnet Thinking 版 在 8k token 內理解力穩定,且邏輯一致性明顯優於 Claude 3.5。
- DeepSeek R1 表現超越 o3-mini,是預算有限使用者的高性價比選擇。
- GPT-4.5 Preview 與 GPT-4.1 雖無特殊推理設定,但在大部分 context 下表現穩定。
- qwq-32b 表現出色,超越 DeepSeek 並穩居前段,尤其在 32k 內保持高分。
- LLaMA-4 Maverick 與 Scout 則令人失望,表現不如 LLaMA 3.3,長文理解力嚴重不足。
🔎 精選模型表現一覽(8k / 32k / 120k Token)
| 模型 | 8k 分數 | 32k 分數 | 120k 分數 |
|---|---|---|---|
| Gemini 2.5 Pro | 86.1 | 83.3 | 90.6 ✅ |
| Claude 3.7 Sonnet Thinking | 83.3 | 75.0 | 53.1 |
| DeepSeek R1 | 69.4 | 63.9 | 33.3 |
| GPT-4.5 Preview | 72.2 | 66.7 | 63.9 |
| qwq-32b:free | 86.1 | 80.6 | 61.1 |
| o3-mini | 50.0 | 44.4 | 43.8 ❌ |
| LLaMA-4 Scout | 40.0 | 16.0 | 27.3 ❌ |
🧠 為何這個測試比其他 Benchmark 更「難」?
市面上很多測試(如 LongBench、Needle-in-Haystack)偏重「搜尋正確答案」,而 Fiction.LiveBench 則關注深度理解、情感邏輯與故事整體感知。這些都是小說創作時 LLM 真正需要具備的能力。
🗒️ 結語:哪個模型才是寫小說的好幫手?
對小說創作者而言,真正可用於創作的 LLM 終於出現了 —— Gemini 2.5 Pro 領先業界,Claude、GPT-4.5、DeepSeek R1、qwq-32b 也各有亮眼表現。
🔗 全部詳細數據與測試方法,請見原始報告:
👉 Fiction.LiveBench 全文與排行榜
🖼️ AI 圖庫|抄咒語學玩法
想睇吓人哋點玩 AI 畫圖?圖庫集合大量 Flux / Gemini 作品, 可以一 click 複製咒語,直入生成器再改做自己版本。
 Gallery
Gallery
 Gallery
Gallery
 Gallery
Gallery