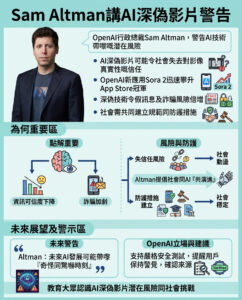
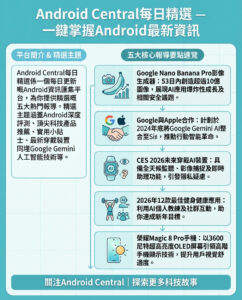
教你打造一個能動態調節自身思考深度的元認知AI代理
今次教學,我哋會建立一個進階嘅元認知控制代理,佢可以學識點樣調節自己嘅思考深度。我哋將推理視為一個連續體,從快速嘅啟發式方法(heuristics)、深度思考鏈(chain-of-thought),到精確嘅工具式解決方案,並訓練一個神經元元控制器(meta-controller)來決定每個任務應該用邊種模式。透過優化準確度、計算成本同有限嘅推理預算之間嘅權衡,我哋探索呢個代理點樣監控自己嘅內部狀態,並即時調整推理策略。每一步我哋都會實驗、觀察模式,理解當代理學識反思自己嘅思考時,元認知點樣自然浮現。詳情可參考【完整代碼筆記本】。
建立任務環境與推理模式
我哋先設計個世界俾元代理運作。隨機產生加法或乘法嘅算術任務,定義正確答案,估計難度,並實現三種不同嘅推理模式:
1. 快速啟發式(fast heuristic):速度快但準確度較低,帶有一定隨機噪音。
2. 深度思考鏈(deep chain-of-thought):模擬逐位計算,較慢但準確度高。
3. 工具求解器(tool solver):直接用精確嘅計算工具解決,成本最高。
呢啲模式喺準確度同計算成本上表現唔同,形成代理決策嘅基礎。
任務狀態編碼與策略網絡
每個任務會被編碼成一個狀態向量,包含兩個操作數嘅正規化值、操作符類型、估計嘅困難度、剩餘推理預算、錯誤率指數移動平均(EMA)同上一次採取嘅行動。呢個狀態會輸入一個神經網絡策略模型,輸出三種行動嘅概率分佈。透過呢個策略,代理學識點樣根據當前任務同自身狀態選擇最合適嘅推理模式。
利用REINFORCE策略梯度進行訓練
核心學習機制係用REINFORCE策略梯度演算法。代理喺多步任務序列中收集行動嘅log概率同獎勵,計算回報並更新策略。獎勵設計上,成功解答獲得正分,但會扣除計算成本嘅懲罰,超出預算更有額外罰分。透過訓練,代理逐漸學識平衡準確度同計算資源,選擇合適嘅推理策略。
訓練結果與行為評估
訓練數百集後,我哋分析代理喺不同難度任務中嘅行為。結果顯示,代理喺簡單任務多用快速啟發式,而面對困難任務時會選擇深度思考或工具求解,展現出智能調節推理深度嘅能力。透過評估,我哋見證策略隨訓練不斷優化。
示例:硬任務嘅元認知思考模式選擇
我哋用一個硬任務(47乘以18)測試訓練好嘅代理,觀察佢點樣選擇推理模式。代理根據當時狀態,選擇咗最合適嘅推理途徑,並完成計算。呢個示例清楚展示元認知控制如何實際運作,令代理可以因應任務調整思考方式。
總結
呢個教程示範咗一個神經元控制器點樣學識動態選擇推理路徑,根據任務難度同當刻限制,調節思考深度。代理喺不斷嘗試中,發現快速啟發式適合簡單任務,深度推理適合難度較高嘅任務,而精確工具則喺必要時刻發揮關鍵作用。呢種元認知控制有效提升決策效率,令AI系統更靈活同智能。
—
個人評論與啟發
呢篇教學好成功地將元認知概念實踐喺AI代理身上,唔止係理論層面,而係透過具體代碼同訓練流程,展示點樣令AI學識「思考自己嘅思考」。呢種能力對未來AI發展至關重要,因為佢令系統唔單止盲目執行,而係能夠根據任務特性同資源限制作出智慧調整。
特別係訓練中引入計算成本同預算限制,令模型唔會無限制用最精確但昂貴嘅方法,反映現實世界中資源有限嘅挑戰。呢個角度值得其他AI研究借鑒,尤其喺邊緣計算或移動設備上,效率同準確度嘅平衡更為關鍵。
不過,現時例子仍屬較簡單嘅算術任務,未來可以考慮擴展到更複雜嘅推理場景,例如語言理解、決策規劃等領域。元認知控制同樣可以幫助AI在多任務、多目標環境中更靈活調整策略,提升整體智能水平。
最後,呢種元認知AI代理有潛力成為自主學習同自我優化嘅基礎,喺人工智能向真正自主智能邁進嘅路上,係一個重要嘅里程碑。希望未來能見到更多相關研究,將元認知能力推向更高層次。
—
想深入了解代碼同實驗細節,可以參考【完整代碼筆記本】,親自試玩同修改,體驗元認知AI嘅奧妙。
以上文章由特價GPT API KEY所翻譯及撰寫。而圖片則由FLUX根據內容自動生成。