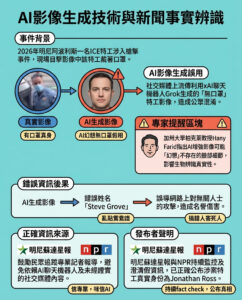
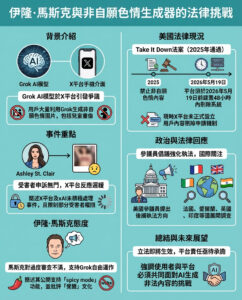
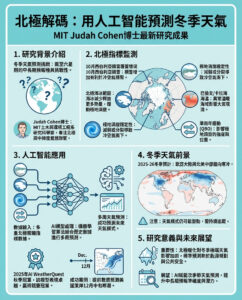
少樣本偏好優化(FSPO):一個旨在建模偏好數據集中的多樣子群體的創新機器學習框架
個性化大型語言模型(LLMs)對於虛擬助手和內容推薦等應用至關重要,確保回應符合個別用戶的偏好。與傳統方法根據聚合的用戶反饋來優化模型不同,個性化旨在捕捉由文化、經驗和價值觀塑造的個體視角的多樣性。目前的優化方法,例如基於人類反饋的強化學習(RLHF),專注於單一獎勵模型,可能忽視少數群體的觀點並引入偏見。一個更有效的方法是學習獎勵函數的分佈而不是單一的獎勵函數,這樣能讓LLMs生成針對不同用戶群體的回應。這種轉變不僅提高了用戶滿意度,還通過承認多樣的視角來促進包容性。然而,在開放式問題回答及現實應用中有效實施這一點仍然具有挑戰性。
在偏好學習的研究中,已探討了多種個性化策略。一些方法,如分佈對齊,旨在將模型輸出與廣泛的統計特性相匹配,但缺乏對個別用戶的直接適應。另一些方法則試圖明確建模獎勵分佈,但在樣本效率和現實世界評估方面面臨挑戰。許多現有方法,例如GPO和基於人類修正的方法,在結構化任務中表現良好,但尚未經過充分測試以進行開放式個性化。監督微調、強化學習技術如PPO,以及其他方法如DPO和IPO已被探索用於基於用戶偏好來細化LLM輸出。FSPO作為一種黑箱元學習方法,能夠以最少的示例適應新的用戶偏好,並利用先前在語言建模、強化學習和元學習中的技術。
來自斯坦福大學、谷歌DeepMind和OpenAI的研究人員提出了少樣本偏好優化(FSPO)框架,通過以最少的標記例子適應用戶偏好來個性化語言模型。FSPO不再依賴於聚合的人類反饋,而是將獎勵建模重新定義為一個元學習問題,使模型能夠構建個性化的獎勵函數。該方法生成超過一百萬個結構化的合成偏好,以解決數據稀缺的問題。FSPO在三個領域(評論、教育適應和角色扮演)進行評估,在合成用戶個性化中獲得87%的勝率,與真實用戶的勝率為72%,增強了LLMs在開放式互動中與多樣用戶需求的對齊能力。
FSPO框架將個性化視為一個元學習問題。傳統的RLHF微調方法將用戶偏好聚合在整個人群中,經常邊緣化個別差異。FSPO通過將偏好與用戶特定標識符相關聯來解決這一問題,並將每個用戶建模為一個任務實例。使用黑箱元學習方法,它能夠快速適應新用戶,並且所需數據極少。FSPO構建少樣本提示,利用預訓練的LLMs進行有效的個性化。此外,用戶表示被框架為(N)-位偏好編碼,允許結構化的泛化。FSPO在三個領域進行評估:評論、教育解釋和基於角色的問題回答。
FSPO的評估對比了四個基準:1)通用指令模型,2)少樣本提示,3)少樣本微調(Pref-FT),和4)使用神諭用戶描述的提示。FSPO在各種任務中始終優於這些基準。通過修改的AlpacaEval評估的合成勝率顯示,FSPO在ELIX、Review和Roleplay任務中表現出色,真實用戶的勝率達到82.6%。一項有25名參與者的人類研究證實了FSPO的有效性,與基礎和SFT模型相比,勝率為72%。FSPO展現了強大的個性化能力,通過連鎖思考推理縮小了與神諭性能的差距。
總結來說,FSPO是一個通過元學習模型多樣人類偏好的框架,旨在開放式問題回答中對語言模型進行個性化。與傳統的獎勵建模不同,FSPO能夠快速適應個別用戶,僅需少量標記偏好。生成超過一百萬個合成個性化偏好以應對數據稀缺問題,確保了有效現實轉移的多樣性和一致性。FSPO在三個領域和1500名合成用戶的評估中達到87%的AlpacaEval勝率,並與真實用戶的勝率為72%。這一方法增強了虛擬助手和內容策劃應用中的個性化,促進了更加包容和以用戶為中心的語言模型的發展。
這項研究展示了AI在個性化領域的新進展,為未來的應用提供了新的可能性。FSPO不僅提升了語言模型的能力,還為用戶提供了更具針對性的回應,這對於提升用戶體驗至關重要。在科技快速發展的今天,這樣的研究有助於我們理解如何更好地利用AI技術來滿足多元化的需求,並推動個性化服務的邊界。
以上文章由特價GPT API KEY所翻譯及撰寫。而圖片則由FLUX根據內容自動生成。