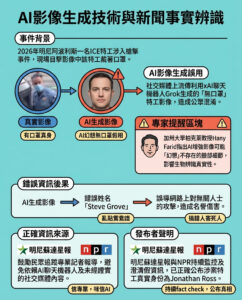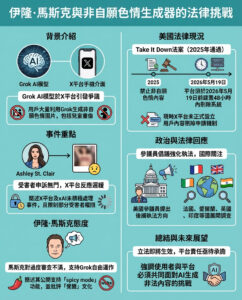
認識變壓器:谷歌突破如何重寫人工智能的藍圖
在2017年夏季,一群谷歌大腦的研究人員悄然發布了一篇論文,這篇論文將永遠改變人工智能的發展軌跡。這篇名為《注意力就是一切》的學術出版物並未以華麗的主題演講或頭條新聞的形式出現,而是在神經信息處理系統(NeurIPS)會議上首次亮相,這是一個技術聚會,尖端的想法往往需要數年時間才能進入主流。
當時,外界對這篇論文知之甚少,但它為如今幾乎所有主要的生成式人工智能模型奠定了基礎,從OpenAI的GPT到Meta的LLaMA變體、BERT、Claude、Bard等。
變壓器是一種創新的神經網絡架構,顛覆了序列處理的舊假設。與其逐步線性處理,變壓器採用了一種可並行化的機制,基於一種稱為自注意力的技術。在幾個月內,變壓器徹底改變了機器理解語言的方式。
一種新模型
在變壓器出現之前,最先進的自然語言處理(NLP)主要依賴循環神經網絡(RNN)及其改進版本——長短期記憶網絡(LSTM)和門控循環單元(GRU)。這些循環神經網絡逐字(或逐標記)處理文本,並傳遞一個隱藏狀態,旨在編碼到目前為止所讀取的一切。
這一過程看似直觀……畢竟,我們是從左到右閱讀語言,那麼為什麼模型不這樣做呢?
但這些舊架構存在著關鍵的缺陷。例如,它們在處理非常長的句子時會遇到困難。當LSTM到達段落末尾時,開頭的上下文往往已經像是模糊的記憶。由於每一步都依賴於前一步,並行化也變得困難。這個領域迫切需要一種方法,來處理序列而不被困在線性模式中。
谷歌大腦的研究人員決定改變這種動態。他們的解決方案看似簡單:完全拋棄循環。相反,他們設計了一種可以同時查看句子中每個單詞並找出每個單詞之間關係的模型。
這一巧妙的技巧稱為“注意力機制”,使得模型能夠專注於句子中最相關的部分,而不需循環的計算負擔。結果就是變壓器:快速、可並行化,並且在處理長文本的上下文方面表現異常出色。
突破性想法在於“注意力”,而不是序列記憶,可能是理解語言的真正引擎。雖然早期模型中已存在注意力機制,但變壓器將注意力提升為主角。如果沒有變壓器的全注意力框架,當今的生成式人工智能可能仍然陷於較慢的、有限的範式中。
意外與人工智能
那麼,這一想法是如何在谷歌大腦中產生的呢?背後的故事充滿了偶然與智力的交叉滲透,這是人工智能研究的特徵。內部人士談到非正式的腦力激盪會議,研究人員來自不同團隊,交流注意力機制如何幫助解決翻譯任務或改善源句與目標句之間的對齊。
有關循環必要性的辯論在咖啡室中展開,研究人員回憶起“走廊輔導會議”,在這裡一個當時激進的想法——完全移除RNN——被提出、挑戰並完善,最終團隊決定將其編碼實現。
變壓器的設計亮點之一在於,它使得在巨大的數據集上進行快速高效的訓練成為可能。早期開發變壓器的時候,有些谷歌工程師最初並未意識到這一模型的潛力。他們知道它好得多,遠超過某些語言任務的舊RNN模型,但認識到這可能徹底改變整個人工智能領域的想法仍在發展中。直到架構公開發布,全球的愛好者開始實驗,變壓器的真正威力才變得不可否認。
語言模型的文藝復興
當谷歌大腦在2017年發布論文時,NLP社區的反應首先是好奇,然後是驚訝。變壓器架構在WMT英德和英法基準等任務中超越了最佳機器翻譯模型。但不僅僅是性能——研究人員迅速意識到變壓器的並行化能力遠超過以往。訓練時間驟降,曾經需要數天或數周的任務在同樣的硬件上可以在短時間內完成。
在其推出的一年內,變壓器模型激發了一波創新。谷歌利用變壓器架構創建了BERT(雙向編碼器表示變壓器),顯著改善了機器對語言的理解,並在許多NLP基準中名列前茅。它很快進入日常產品,如谷歌搜索,默默提升了查詢的解釋方式。
媒體發現了GPT的能力,展示了無數例子——有時驚人,有時則搞笑。
幾乎同時,OpenAI將變壓器藍圖帶入另一個方向,推出了GPT(生成式預訓練變壓器)。GPT-1和GPT-2暗示了擴展的力量。到了GPT-3,這些系統在生成類人文本和通過複雜提示推理方面的能力變得無法忽視。
第一版ChatGPT(2022年底)使用了進一步改進的GPT-3.5模型,這是一個關鍵時刻。ChatGPT能夠生成驚人一致的文本,翻譯語言,編寫代碼片段,甚至創作詩歌。突然間,機器生成類人文本的能力不再是遙不可及的夢想,而是一種可觸及的現實。
隨處可見的注意力
ChatGPT已經成為一種文化現象,從技術圈和行業討論中脫穎而出,引發了關於AI生成內容的家庭聚會話題。即使是對技術不太熟悉的人也開始意識到“有這種AI可以為我寫東西”或“像人一樣與我交談”的想法。
然而,所有技術革命都有副作用,變壓器對生成式人工智能的影響也不例外。即使在這個早期階段,生成式AI模型已經帶來了合成媒體的新時代,並引發了有關版權、錯誤信息、公眾人物冒充和倫理部署的棘手問題。
同樣的變壓器模型能夠生成令人信服的人類散文,也能產生錯誤信息和有害內容。偏見可能存在於訓練數據中,並可能在生成式AI模型的回應中微妙地嵌入和放大。因此,各國政府和監管機構開始密切關注。我們如何確保這些模型不成為錯誤信息的引擎?當模型可以按需生成文本和圖像時,我們如何保護知識產權?
研究人員與開發當今主導模型的公司已經開始整合公平性檢查,建立保護措施,並優先考慮生成式AI的負責任部署(或者說他們這麼說)。然而,這些努力在一個模糊的環境中展開,因為關於這些模型的訓練方式和大型科技公司如何獲取訓練數據仍然存在重大問題。
《注意力就是一切》這篇論文仍然見證了開放研究如何推動全球創新。通過公開所有關鍵細節,這篇論文允許任何人——競爭者或合作者——基於其想法進行構建。谷歌團隊的開放精神促進了變壓器架構在整個行業迅速傳播的驚人速度。
我們才剛開始看到,隨著這些模型變得更加專業、高效和廣泛可及,會發生什麼。機器學習社區迫切需要一種能夠處理複雜性的模型,而自注意力至今為止已經交付了成果。從機器翻譯到能夠展開多樣對話的聊天機器人,從圖像分類到代碼生成,變壓器已成為自然語言處理的默認支柱。但研究人員仍在思考:注意力真的就是我們所需的一切嗎?
隨著新架構的出現,如Performer、Longformer和Reformer,旨在提高對非常長序列的注意力效率,這個領域絕非停滯不前。
前進的道路上,每一個新提案都會受到審視、興奮,甚至不妨說,有些人會感到恐懼。
以上文章由特價GPT API KEY所翻譯及撰寫。而圖片則由FLUX根據內容自動生成。