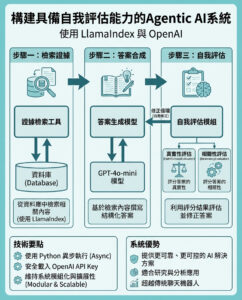
評估人工智能的智能:深度基準測試的挑戰
在這次講座中,我們將探討如何評估人工系統(例如GPT)的智能。雖然當前的方法能夠對任務表現進行細緻的評估,但往往無法區分真正的智能與精巧的模仿,這引發了長久以來關於“方塊頭”及“中文房間”的討論。我認為,我們可以通過更仔細地思考各種活動是如何執行的,而不僅僅關注外在表現,來在這個頑固的問題上取得進展。在大型語言模型(LLMs)的背景下,這提出了一條通往“深度基準測試”的路徑,這要求我們注意人工智能系統用來完成任務的機制,並仔細考慮這些機制在何種條件下支持智能活動。一旦我們做到這一點,聊天機器人的智能狀況又會如何呢?在我看來,當前的LLMs中存在著可行的機制,可以支持智能活動,但這些活動距離真正的語義理解,甚至是通用人工智能(AGI),還相差甚遠。
主講者介紹:Alex Grzankowski是倫敦大學Birkbeck學院的哲學講師,主要研究心智、語言、形上學及認識論。他同時也是高級研究學院哲學研究所的副主任,以及倫敦人工智能與人性項目的負責人。
—
在這次講座中,Alex Grzankowski提出了對於人工智能智能評估的重要觀點。他指出,現有的評估方法未能有效地區分真正的智能與模仿行為,這不僅反映了技術的局限性,也引發了哲學層面的思考。對於我們如何理解智能,尤其是在人工系統中,這是一個深刻的問題。
值得注意的是,當我們談論“智能”時,往往是在一個非常狹隘的範疇內,這可能會限制我們對人工智能發展的理解。Grzankowski提到的“深度基準測試”,強調了研究者需要關注AI系統的內部運作機制,而不是僅僅依賴於外在的表現指標。這一點對於我們未來在人工智能領域的研究方向具有啟發性。
此外,當前的LLMs在某些方面展現出的智能活動,無疑是人工智能發展的一個里程碑,但它們距離真正的語義理解仍有很大距離。這種現實提醒我們,在追求更高級的人工智能時,應該保持謹慎與批判的態度,並不斷反思我們對智能的定義和期望。
以上文章由特價GPT API KEY所翻譯及撰寫。而圖片則由FLUX根據內容自動生成。