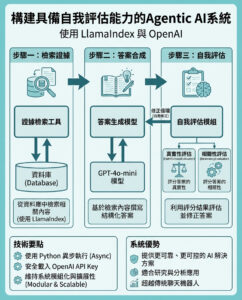
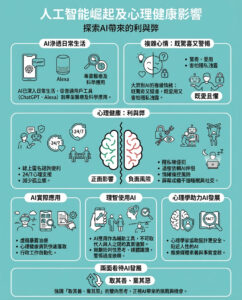
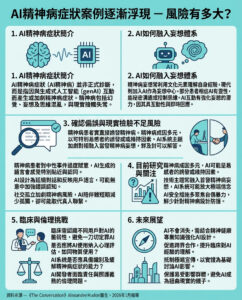
當人工智能通過這個測試時,請小心
一些新創的測試名為「人類的最後考試」,其創始人認為我們可能很快就無法設計出足夠困難的測試來挑戰人工智能模型。
人工智能的測試挑戰
如果你在尋找一個新的理由來擔心人工智能,可以看看這個:世界上一些最聰明的人正在努力設計出無法被人工智能系統通過的測試。
多年來,人工智能系統的表現是通過各種標準化的基準測試來衡量的。這些測試通常包含數學、科學和邏輯等領域的挑戰性問題,類似於SAT考試。通過比較模型隨時間的得分,研究者可以粗略衡量人工智能的進步。
然而,隨著人工智能系統在這些測試中表現得越來越出色,研究者們不得不創造出更新、更難的測試,這些測試常常包含研究生可能會遇到的考題。
但這些新測試的情況也不太樂觀。來自OpenAI、Google和Anthropic等公司的新模型在許多博士級挑戰中得分很高,這限制了這些測試的實用性,並引發了一個令人擔憂的問題:人工智能系統是否變得太聰明,以至於我們無法有效測量?
本週,來自人工智能安全中心和Scale AI的研究人員將發佈一個可能的答案:一項名為「人類的最後考試」的新評估,他們聲稱這是有史以來對人工智能系統進行的最艱難的測試。
「人類的最後考試」的創始人是丹·亨德里克斯(Dan Hendrycks),他是一位知名的人工智能安全研究者,也是人工智能安全中心的主任。(這項測試的原名「人類的最後防線」被棄用,因為過於戲劇化。)
評論
隨著人工智能技術的快速發展,這種情況引發了深思。傳統的測試方式顯然已經無法滿足當前的需求,這不僅是對我們教育和測評體系的挑戰,更是對人工智能本身的挑戰。若人工智能能夠輕鬆通過人類設計的測試,那麼我們在未來的工作、生活以及倫理決策中將面臨何種影響?
「人類的最後考試」的推出,或許是一個警示,提醒我們需要重新思考測評的標準,並探索更具挑戰性和創新性的方式來評估人工智能的能力。同時,這也讓我們思考:在這場與人工智能的競賽中,我們究竟應該如何設置界限,以確保人類在技術進步中不會失去主導地位。這不僅是技術的問題,更是人類未來的選擇。
以上文章由特價GPT API KEY所翻譯及撰寫。而圖片則由FLUX根據內容自動生成。