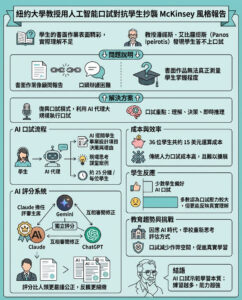
中國開源AI DeepSeek R1 以98%更低成本匹配OpenAI的o1
中國AI研究人員實現了許多人認為遙不可及的目標:一個免費的開源AI模型,能夠匹配或超越OpenAI最先進的推理系統的性能。更令人驚訝的是,他們是如何做到的:通過讓AI通過試錯學習,類似於人類的學習方式。
“DeepSeek-R1-Zero是一個通過大規模強化學習(RL)訓練的模型,沒有經過監督微調(SFT)作為初步步驟,展示了卓越的推理能力。”研究論文中這樣寫道。
“強化學習”是一種方法,其中模型因做出良好決策而獲得獎勵,因做出不良決策而受到懲罰,而無需知道哪一個是正確的。在一系列決策之後,它學會遵循那些結果加強的路徑。
最初,在監督微調階段,一組人類告訴模型他們想要的輸出,給予它知道什麼是好的,什麼是不好的背景。這導致了下一階段,即強化學習,在這一階段中,模型提供不同的輸出,人類對最佳的輸出進行排名。這一過程反復進行,直到模型知道如何穩定地提供滿意的結果。
DeepSeek R1在AI開發中是一個重要的進展,因為人類在訓練過程中的參與最小。與其他基於大量監督數據進行訓練的模型不同,DeepSeek R1主要通過機械強化學習學習——本質上是通過實驗和獲取反饋來理解事物。
“通過RL,DeepSeek-R1-Zero自然出現了許多強大而有趣的推理行為,”研究人員在論文中表示。該模型甚至在沒有明確編程的情況下發展出自我驗證和反思等複雜能力。
隨著模型訓練過程的推進,它自然學會在複雜問題上分配更多的“思考時間”,並發展出捕捉自身錯誤的能力。研究人員強調了一個“頓悟時刻”,模型學會重新評估其對問題的初步方法——這是它並未被明確編程去做的事情。
其性能數據令人印象深刻。在AIME 2024數學基準測試中,DeepSeek R1達到了79.8%的成功率,超越了OpenAI的o1推理模型。在標準化編碼測試中,它表現出“專家級”性能,在Codeforces上達到了2029的Elo評級,超越了96.3%的人工競爭者。
但真正使DeepSeek R1脫穎而出的,是它的成本——或說缺乏成本。該模型的查詢成本僅為每百萬個標記0.14美元,與OpenAI的7.50美元相比,便宜了98%。而且與專有模型不同,DeepSeek R1的代碼和訓練方法完全開源,根據MIT許可證,任何人都可以獲取、使用和修改該模型而不受限制。
AI領域的反應
DeepSeek R1的發布引發了AI行業領導者的強烈反應,許多人強調一個完全開源模型在推理能力上能夠匹配專有領導者的重要性。
Nvidia的首席研究員Jim Fan博士給出了最尖銳的評論,直接將其與OpenAI的原始使命進行對比。“我們生活在一個非美國公司保持OpenAI原始使命的時代——真正開放的前沿研究,賦能所有人,”Fan指出,讚揚DeepSeek前所未有的透明度。
Fan強調了DeepSeek強化學習方法的重要性:“他們或許是第一個顯示出強化學習持續增長的開源項目。”他還讚揚DeepSeek對“原始算法和matplotlib學習曲線”的直截了當分享,與行業中更常見的炒作驅動公告形成對比。
Apple的研究員Awni Hannun提到,人們可以在自己的Mac上運行量化版本的模型。
然而,最有趣的反應來自於對開源行業與專有模型接近程度的思考,以及這一發展對OpenAI作為推理AI模型領導者的潛在影響。
Stability AI的創始人Emad Mostaque採取了一種挑釁的立場,暗示這一發布給資金更雄厚的競爭者施加了壓力:“你能想像一個籌集了十億美元的前沿實驗室,如今無法發布最新模型,因為它無法超越DeepSeek嗎?”
這一觀點引發了針對OpenAI的更深層次的思考,因為競爭性開源模型的出現可能會對OpenAI造成潛在的損害,因為這使得其模型對於那些本可以願意花很多錢的高端用戶變得不那麼吸引。
總的來說,DeepSeek R1的出現不僅是技術上的突破,更是對市場格局的挑戰。這一模型的開源性質和低成本使其成為未來AI發展的重要參考,並可能改變用戶對於AI技術的接受度及使用方式。
這一切都表明,開源AI的潛力正在被重新定義,未來的推理AI模型可能會在公正性、可及性和性能上達到新的高度。
以上文章由特價GPT API KEY所翻譯及撰寫。而圖片則由FLUX根據內容自動生成。
🖼️ AI 圖庫|抄咒語學玩法
想睇吓人哋點玩 AI 畫圖?圖庫集合大量 Flux / Gemini 作品, 可以一 click 複製咒語,直入生成器再改做自己版本。
 Gallery
Gallery
 Gallery
Gallery
 Gallery
Gallery