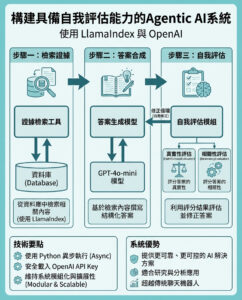
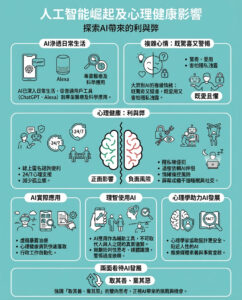
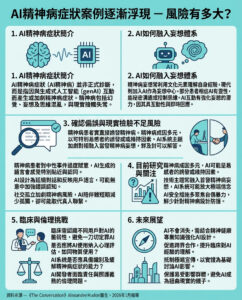
**Google的最新對手:Perplexity AI是什麼,為何引起如此多爭議?**
由Jeff Bezos支持的AI初創公司希望利用大型語言模型(LLMs)挑戰Google在搜索引擎市場的地位,但卻引發不少爭議。
人工智能(AI)初創公司正掀起波瀾,Perplexity AI成為最新的焦點。Perplexity是一個AI驅動的搜索引擎和聊天機器人,從其認為可信的網頁中搜集信息,並用自己的工具提供摘要。
這家公司希望在Google主導的搜索引擎市場中打開一個新局面。Perplexity表示,其使命是「民主化知識的獲取」,讓每個人更容易學習和探索新主題。
根據《華爾街日報》,該公司目前每天處理約1500萬個查詢。
**它如何運作?**
Perplexity使用多個大型語言模型(LLMs),如OpenAI和Meta的Llama,來生成搜索摘要。
但與Google等公司有何不同?
傳統搜索引擎使用預先索引的數據,但Perplexity進行實時搜索,這使它在快速變化的主題(如新聞)中更具效能。與其他搜索引擎提供的鏈接列表不同,Perplexity聲稱以「清晰、日常的語言」給出答案。
此外,它還顯示用於回答的來源鏈接,讓用戶知道信息的來源。
**它是如何開始的?**
Perplexity於2022年由Andy Konwinski、Aravind Srinivas、Denis Yarats和Johnny Ho創立,他們是在Google AI工作時相識的。公司總部位於美國舊金山灣區,由多家風險投資公司提供資金支持,並得到亞馬遜創始人Jeff Bezos的支持。
**為何突然引起關注?**
根據《華爾街日報》的報導,該公司正在進行籌款談判,希望以80億美元的估值籌集約5億美元。這將使公司的估值翻倍。
但對Perplexity來說,並非一切都是好消息。一些新聞出版商,包括《紐約時報》、《福布斯》和《連線》,以及媒體大亨Rupert Murdoch的道瓊斯和《紐約郵報》,指控該公司抄襲和網頁抓取,部分投訴甚至導致訴訟。
這些訴訟的一個例子是Murdoch的媒體帝國指控Perplexity策劃了一個方案,以免費訓練其模型,從而將流量從出版商的網站轉移走,這對他們的收入至關重要。
這些訴訟是科技公司和出版商之間更廣泛的版權爭端的一部分,涉及在未經許可的情況下使用新聞文章和其他內容來運行他們的系統。
新聞公司認為Perplexity在其內部數據庫中攝取內容,使用一種稱為檢索增強生成(Rag)的技術來生成對用戶問題的回應。
Perplexity用戶還可以「跳過鏈接」到原始出版商。
原告還認為,Perplexity以某種方式構建其回應,可以逐字重現內容。
今年七月,Perplexity宣佈了一個針對出版商的收益共享模式。
「當Perplexity從引用出版商內容的互動中獲得收入時,該出版商也將獲得一部分收益。」Perplexity在一篇博客文章中寫道,並補充說,公司將向出版商提供應用程序編程接口(API)積分。
**評論:**
Perplexity AI的崛起反映了科技行業的迅速變化及其對傳統市場的挑戰。這家公司試圖以其獨特的實時搜索功能顛覆Google的霸主地位,但同時也面臨著嚴重的法律挑戰。這不僅是科技與傳媒之間的衝突,亦反映了數碼內容版權在AI時代的複雜性。這場法律戰可能會對未來AI技術的發展產生深遠影響,特別是在如何合法使用和保護數碼內容方面。隨著AI技術的進一步發展,這類版權問題將變得愈加複雜和重要。
以上文章由特價GPT API KEY所翻譯