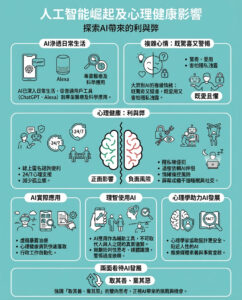
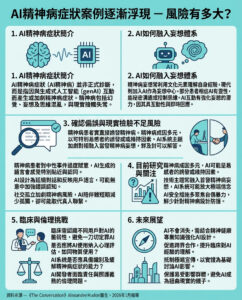
Moonshine:快速、準確且輕量化的語音轉文字模型,適用於邊緣設備的轉錄和語音指令處理
語音識別技術在現代應用中越來越重要,特別是在實時轉錄和語音激活的指令系統中。這些技術對於聽力障礙人士的輔助工具、演講時的即時字幕以及智慧設備中的語音控制都至關重要。這些應用需要即時且精確的反饋,尤其是在計算能力有限的設備上。隨著這些技術擴展到更小、更具成本效益的硬件中,高效和快速的語音識別系統的需求變得更加迫切。尤其是那些在沒有穩定互聯網連接的設備上運行的系統,面臨著更多挑戰,因此需要能在這種受限環境中運行良好的解決方案。
降低延遲的挑戰
實時語音識別的主要挑戰之一是降低延遲,即從話語到轉錄的時間差。傳統模型難以在有限的計算資源環境中平衡速度與準確性。對於需要近乎即時結果的應用,任何轉錄延遲都可能嚴重影響用戶體驗。此外,許多現有系統以固定長度的塊處理音頻,不論實際語音長度如何,導致不必要的計算工作。這種方法在處理長音頻段時功能尚可,但在處理較短或長度不一的輸入時,會造成效率低下,增加不必要的延遲和性能下降。
由於其高準確性,OpenAI 的 Whisper 一直是通用語音識別的首選模型。然而,它使用固定長度編碼器,以 30 秒塊處理音頻,對較短序列需要零填充。這種填充創造了恆定的計算負擔,即使音頻輸入很短,也會增加整體處理時間,降低效率。雖然 Whisper 在長格式轉錄中具有高準確性,但在需要實時反饋的設備應用中,它難以滿足低延遲需求。
Moonshine 模型的突破
為了解決這些低效問題,Useful Sensors 的研究人員推出了 Moonshine 系列語音識別模型。Moonshine 模型採用可變長度編碼器,根據音頻輸入的實際長度調整計算處理,從而避免了零填充的需要。這一突破使得這些模型在資源受限的環境中,如低成本設備上,能夠更快、更高效地運行。Moonshine 的設計目標是匹配 Whisper 的高轉錄準確性,但計算需求顯著降低,使其更適合實時轉錄任務。通過使用先進技術如旋轉位置嵌入 (RoPE),該模型確保每個語音片段都能高效處理,提升整體性能。
Moonshine 的核心架構基於編碼器-解碼器的變壓器模型,消除了傳統的手工設計特徵如梅爾頻譜圖。Moonshine 直接處理原始音頻輸入,使用三個卷積層將音頻壓縮至 384 倍,相比 Whisper 的 320 倍壓縮。此外,Moonshine 在超過 90,000 小時的公開 ASR 數據集以及研究人員自有數據集的 100,000 小時上進行訓練,總計 200,000 小時的訓練數據。這龐大且多樣的數據集使 Moonshine 能夠更準確地處理各種音頻輸入,從不同長度到多樣口音。
測試結果與性能
在與 OpenAI 的 Whisper 的測試中,結果顯示,Moonshine 對於 10 秒語音片段的處理速度可達到五倍之快,而字錯誤率(WER)並未上升。例如,Moonshine Tiny 是該系列中最小的模型,與 Whisper Tiny 相比,其計算需求減少了五倍,同時保持了相似的 WER 分數。就特定基準而言,Moonshine 模型在大多數數據集中,如 LibriSpeech、TEDLIUM 和 GigaSpeech,表現均優於 Whisper,且在不同音頻時長上具備較低的 WER。Moonshine Tiny 的平均 WER 為 12.81%,而 Whisper Tiny 為 12.66%。雖然兩者表現相似,但 Moonshine 的優勢在於其處理速度和對較短輸入的可擴展性。
研究人員還強調了 Moonshine 在嘈雜環境中的表現。在對具有不同信噪比(SNR)的音頻進行評估時,如計算機風扇的背景噪音,Moonshine 在較低 SNR 水平下保持了優越的轉錄準確性。其對噪音的穩健性,加上高效處理可變長度輸入的能力,使得 Moonshine 成為實時應用的理想解決方案,即使在不理想的條件下也能保持高性能。
研究重點
1. Moonshine 模型對於 10 秒語音片段的處理速度比 Whisper 模型快達 5 倍。
2. 可變長度編碼器消除了零填充的需要,減少了計算負擔。
3. Moonshine 在 200,000 小時的數據上進行訓練,包括開放和內部收集的數據。
4. 最小的 Moonshine 模型(Tiny)在各種數據集上的平均 WER 為 12.81%,可與 Whisper Tiny 的 12.66% 相媲美。
5. Moonshine 模型在噪音和不同 SNR 水平下展示了優越的穩健性,適合資源受限設備的實時應用。
結論
研究團隊解決了實時語音識別中的一個重大挑戰:在保持準確性的同時降低延遲。Moonshine 模型透過使用可變長度編碼器,提供了一個高效的替代方案,相對於傳統的 ASR 模型如 Whisper。這一創新帶來了更快的處理速度、減少的計算需求和相當的準確性,使得 Moonshine 成為低資源環境中的理想解決方案。通過在廣泛的數據集上進行訓練並使用尖端的變壓器架構,研究人員開發了一系列高度適用於現實世界語音識別任務的模型,從現場轉錄到智慧設備集成。
評論
Moonshine 模型的出現標誌著語音識別技術的一個重要進展,特別是在資源受限的設備上。其可變長度編碼器的設計不僅提高了處理效率,還大大降低了計算成本,這對於需要即時反饋的應用尤為關鍵。在香港這樣的城市,智慧城市和智慧家居的應用正逐漸普及,Moonshine 可以為這些應用提供更快、更可靠的語音識別服務。此外,Moonshine 在噪音環境中的穩健性也值得關注,這意味著它在實際使用中更能應對複雜的聲學場景。對於開發者來說,這樣的技術不僅提升了用戶體驗,還有助於推動語音識別技術的普及和應用範圍的擴展。
以上文章由特價GPT API KEY所翻譯