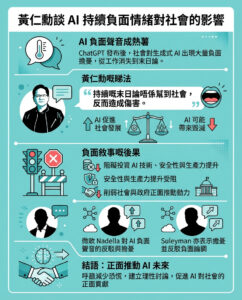
一間初創公司試圖將網絡變成數據庫
一家名為Exa的初創公司正在推廣一種全新的生成搜索技術。它利用大型語言模型背後的技術,聲稱能提供比競爭對手(如Google和OpenAI)更精確的結果。其目標是將互聯網這個龐大而混亂的網頁網絡轉變為一個查詢表,讓用戶的查詢能夠獲得具體且準確的結果。
Exa已經將其搜索引擎作為後端服務提供給希望在其上構建應用程序的公司。今天,它推出了首個消費者版本的搜索引擎,名為Websets。
網絡的無序與組織的夢想
Exa的聯合創始人兼首席執行官Will Bryk表示:“網絡是一個數據的集合,但它非常混亂。這裡有一段Joe Rogan的視頻,那裡有一篇《大西洋月刊》的文章,完全沒有組織。但我們的夢想是讓網絡感覺像一個數據庫。”
Websets的目標是針對那些需要尋找其他搜索引擎無法輕易找到的內容的高階用戶,例如各類人群或公司的類型。用戶如果查詢“製造未來主義硬件的初創公司”,將會得到一個幾百個具體公司的列表,而不是隨機的網頁鏈接。Bryk表示,Google無法做到這一點:“對於投資者、招聘人員或任何希望從網絡獲取數據集的人來說,這裡有很多有價值的用例。”
自從MIT科技評論在2021年報導Google研究人員正在探索使用大型語言模型進行新型搜索引擎的消息以來,事情發展迅速。該想法迅速引起了激烈的批評,但科技公司卻鮮有關注。三年後,Google和Microsoft等巨頭與Perplexity和OpenAI等一系列新興公司競爭,爭奪這一熱門新趨勢的份額。
Exa的獨特之處
Exa不打算(至少目前不打算)超越這些公司,而是提出了一種新的解決方案。大多數其他搜索公司將大型語言模型包裹在現有搜索引擎周圍,利用這些模型來分析用戶的查詢,然後總結結果。但這些搜索引擎本身並沒有太大改變。例如,Perplexity仍然將查詢發送到Google搜索或Bing。可以把當今的AI搜索引擎看作是用新鮮麵包夾著過期的餡料的三明治。
Exa為用戶提供熟悉的鏈接列表,但利用大型語言模型背後的技術重新定義搜索的方式。其基本思想如下:Google通過爬取網絡來建立龐大的關鍵詞索引,然後將其與用戶的查詢匹配。而Exa則通過爬取網絡,將網頁內容編碼為一種稱為“嵌入”的格式,這種格式可以由大型語言模型進行處理。
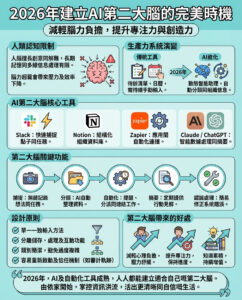
嵌入技術的挑戰
嵌入技術將單詞轉換為數字,使得意義相近的單詞能夠轉換為相似的數值。實際上,這讓Exa能夠捕捉到網頁文本的含義,而不僅僅是關鍵詞。
然而,Exa的這一方法也有其成本。編碼網頁的過程比索引關鍵詞要慢且昂貴。Bryk表示,Exa已經編碼了大約十億個網頁,這在Google的約一萬億個網頁面前顯得微不足道。但Bryk並不認為這是問題:“你不需要編碼整個網絡才能有用。”
Websets在返回結果時速度非常慢,有時候搜索可能需要幾分鐘的時間。但Bryk聲稱這是值得的。他說:“我們的很多客戶開始要求成千上萬的結果,甚至數萬條,他們都願意去喝杯咖啡,然後再回來查看這個龐大的列表。”
用戶體驗的多樣性
斯坦福大學的計算機科學學生Andrew Gao使用過這個搜索引擎,他說:“當我不確定自己要找什麼時,Exa特別有用。例如,查詢‘關於金融中LLMs的有趣博客文章’在Exa上效果比在Perplexity上更佳。”但他也指出,這兩者各有優缺點:“我根據不同的需要使用這兩個搜索引擎。”
Diffbot的首席執行官Mike Tung則表示:“嵌入技術是一種很好的方式來表示現實世界中的人、地點和事物。”但他指出,如果試圖將整個句子或網頁文本編碼成嵌入,則會失去大量信息:“將《戰爭與和平》表示為一個嵌入幾乎會丟失這個故事中發生的所有具體事件,只留下它的類型和時期的一般感覺。”
Bryk承認Exa仍在進行中。他還指出了其他限制。如果你只是想查找一個具體的信息,比如Taylor Swift的男朋友是誰,或者Will Bryk是誰,Exa的表現不如競爭對手:“它會給出很多聽起來像波蘭人的名字,因為我的姓是波蘭的,而嵌入技術在匹配精確關鍵詞方面表現不佳。”
目前,Exa通過在需要時重新引入關鍵詞來解決這個問題。但Bryk對未來持樂觀態度:“我們正在彌補嵌入方法中的不足,直到嵌入方法變得如此出色,以至於我們不需要再彌補這些不足。”
這篇文章引發了我對當前搜索引擎發展的思考。雖然Exa提出了一種新穎的解決方案,但其速度和準確性仍然面臨挑戰。在這個信息爆炸的時代,如何快速獲取準確的信息將成為每個技術公司的核心競爭力。未來,Exa或許需要在技術創新與用戶體驗之間找到一個平衡點,以吸引更多的用戶。
以上文章由特價GPT API KEY所翻譯及撰寫。而圖片則由FLUX根據內容自動生成。