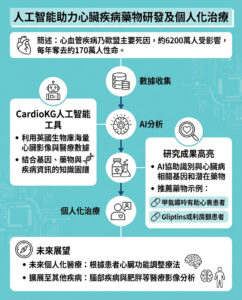
八十三年前的博爾赫斯短篇故事預示著互聯網的陰暗未來
在未來幾十年,互聯網將如何演變?這一直是科幻作家探索的主題。2019年,科幻作家尼爾·史蒂芬森在他的小說《墮落》中描繪了一個近未來的世界,互聯網依然存在,但已經被錯誤信息、虛假信息和廣告污染得幾乎無法使用。小說中的角色通過訂閱“編輯流”來解決這個問題,這是一種人類選擇的新聞和信息,視為可信的來源。然而,這種服務的高昂成本使得只有富人能夠負擔,導致大多數人只能消費質量低劣、未經篩選的網絡內容。
某種程度上,這種情況已經發生:許多新聞機構,如《紐約時報》和《華爾街日報》,將它們的內容放在付費牆後面;同時,社交媒體平台如X(前身為Twitter)和TikTok上錯誤信息猖獗。史蒂芬森作為預言家的記錄相當出色,他在1992年的小說《雪崩》中預見了元宇宙,而在1995年的《鑽石時代》中,則引入了一種類似聊天機器人的互動入門書。
表面上看,聊天機器人似乎提供了解決錯誤信息流行的方案。通過提供事實內容,聊天機器人可以供應高質量的信息來源,而不會被付費牆所阻擋。然而,諷刺的是,這些聊天機器人的輸出可能對未來的網絡構成最大的威脅,這一點在數十年前就已被阿根廷作家博爾赫斯所暗示。
聊天機器人的崛起
目前,互聯網上仍有相當一部分的內容是事實和看似真實的內容,例如經過同行評審、事實檢查或以某種方式驗證的文章和書籍。大型語言模型(LLMs)的開發者利用了這些資源。這些模型要施展魔法,必須攝取大量的高質量文本進行訓練,但問題在於,互聯網雖然龐大,卻是有限的資源。未經剝削的高質量文本正變得稀缺,這導致《紐約時報》所稱的“內容新興危機”。
這迫使像OpenAI這樣的公司與出版商簽訂協議,以獲取更多原材料。然而,根據一項預測,額外的高質量訓練數據的短缺可能在2026年就會出現。隨著聊天機器人的輸出進入網絡,這些第二代文本——包含虛構信息的“幻覺”以及明顯錯誤的建議(例如在比薩上塗膠水)——將進一步污染網絡。如果聊天機器人與錯誤觀點的人互動,它會吸收這些令人厭惡的觀點。2016年,微軟就因Tay這個聊天機器人開始重複種族主義和性別歧視內容而不得不停止其運行。
隨著時間的推移,所有這些問題可能會使在線內容變得比現在更不可信和無用。此外,給低質量內容餵養的LLMs可能會產生更具問題性的輸出,這些輸出也會進入網絡。
無限而無用的圖書館
不難想像,一個反饋循環將導致持續的劣化過程,因為機器人不斷依賴自身的不完美輸出進行學習。2024年7月,《自然》期刊發表了一篇論文,探討了在遞歸生成數據上訓練AI模型的後果。研究顯示,“不可逆缺陷”可能導致這種訓練方式的“模型崩潰”,就像一幅圖像的副本及其副本的副本,將失去對原始圖像的清晰度。
這種情況可能會有多糟?想想博爾赫斯1941年的短篇故事《巴別圖書館》。在計算機科學家蒂姆·伯納斯-李創造網絡架構的五十年前,博爾赫斯已經想象出一個類似的類比。在這篇3000字的故事中,作者想象了一個由無數六邊形房間組成的世界。每個房間的書架上都擺放著相同的書籍,這些書籍的內容必然包含其字母表的所有可能排列。
在博爾赫斯的想象中,這個無盡擴張的內容圖書館中,找到有意義的東西就像在大海撈針。起初,這種認知引發了喜悅:根據定義,必然存在描述人類未來和生命意義的書籍。然而,居民們發現大多數書籍只是毫無意義的字母組合。真相存在,但所有可能的虛假信息也同樣存在,所有這些都埋藏在不可思議的無意義的文字中。
即使經過幾個世紀的搜索,只有少數有意義的片段被找到。而且,即使如此,這些連貫的文本也無法確定是真相還是謊言。希望最終變成絕望。
互聯網是否會變得如此污染,以至於只有富人才能負擔準確和可靠的信息?或者無限的聊天機器人會產生如此多的有害文字,以至於在線尋找準確信息變得像在大海撈針?互聯網常被描述為人類偉大的成就之一,但就像其他資源一樣,我們必須認真考慮如何維護和管理這一資源,否則我們可能會面臨博爾赫斯所描繪的反烏托邦景象。
在這個數位時代,對於信息的質量和來源的關注顯得尤為重要。隨著科技的進步,我們必須保持警惕,避免信息的過度膨脹和質量的下降,確保互聯網能繼續成為知識和真相的寶庫,而不是淪為一個充斥著虛假和低質量內容的無用空間。
以上文章由特價GPT API KEY所翻譯及撰寫。而圖片則由FLUX根據內容自動生成。